VexRiscvでBRAMのかわりにDRAMを使いたい(失敗)
前回のKV260でVexRiscv動作させた - lp6m’s blogでは、VexRiscvのコアのメモリをBRAMで実装していた。 AXI BRAMを使ってPSから読み書きができた。
Xilinx DPUとVexriscvを両方載せようとすると、BRAMリソースが制約を受けてメモリサイズを小さくせざるを得ない。
パフォーマンスを犠牲にしてよいので、BRAMの変わりにDRAMを使いたい。VexRiscvの命令バス(IBus)とデータバス(DBus)はAXIプロトコルなので、適当に繋いだらできるのでは?と思って繋いだ。
ブロックデザインは以下の通り。

アドレスマップは特に何もいじらず、自動で設定されたものを使用した。

教えてもらうまで知らなかったのだが、PS/PLはどのDDRアドレスにでもアクセスできるのではなくて、PS側にはDDR Low(0x0000_0000から0x7FFF_FFFF)にしか割り当てられていない。
VexRiscvにはこのDDR Low領域に読み書きしてもらわないと、PS側からアクセスできないみたい。
うう、、、それはハードコーディングですね。もしこのアドレスが変更可能であれば、PS 側の DRAM 領域内にしてください。例えば Ultra96 ならば 0x7F00_0000 - 0x7FFF_FFFF とかに。というのも、PS 側 にはそもそも0xA000_0000 にはメモリが無いので、共有することができません。
— 隠居したエンジニア (@ikwzm) January 5, 2023
VexRiscvは命令メモリの開始アドレスをハードコーディングするのでresetVectorを0x40000000lに修正した。
github.com
petalinuxプロジェクトのxilinx-kv260-starterkit-2022.1/project-spec/meta-user/recipes-bsp/device-tree/files/system-user.dtsi を修正する。
reserved-memoryでDDR Low領域の一部空間(今回は0x40000000から0x4FFFFFFF)をLinuxに使用されないようにブロックしておく。
CMA領域に連続したメモリアドレスを確保する。この書き方は以下を参考にさせてもらった。
github.com
最後に、確保した空間を簡単に読み書きするために`u-dma-buf`を使用させてもらう。
今までudmabufはXilinx AXI DMA IPのためだけに存在するバッファだと完全に勘違いしていたが、純粋にデータのやりとりのバッファとして使えることを理解した気がする。
/include/ "system-conf.dtsi"
/ {
chosen {
bootargs = "earlycon console=ttyPS1,115200 clk_ignore_unused init_fatal_sh=1 cma=512M uio_pdrv_genirq.of_id=generic-uio";
stdout-path = "serial1:115200n8";
};
reserved-memory {
#address-cells = <2>;
#size-cells = <2>;
ranges;
riscv_buf: riscv_buf@40000000 {
compatible = "shared-dma-pool";
reusable;
reg = <0x0 0x40000000 0x0 0x10000000>;
label = "riscv_buf";
};
};
udmabuf@40000000 {
compatible = "ikwzm,u-dma-buf";
device-name = "udmabuf0";
size = <0x10000000>;
memory-region = <&riscv_buf>;
};
};
この内容で起動用SDカードを作成した。
petalinux-build petalinux-package --boot --u-boot --force petalinux-package --wic --images-dir images/linux/ --bootfiles "ramdisk.cpio.gz.u-boot,boot.scr,Image,system.dtb,system-zynqmp-sck-kv-g-revB.dtb" --disk-name "mmcblk1"
pl.dtsiの作成
xmutilでデバイスツリーオーバレイするためのdtboファイルを作成する。
PL側のノードがないため、エラーになった。 xlnx_rel_v2022.2を指定することでエラーは出なかった。以下リンクと同じエラー。
createdts fails for KV260 XSA · Issue #310 · Xilinx/Vitis-Tutorials · GitHub
xsct createdts -hw vivado/riscv_base_prj/riscv_base_prj.xsa -zocl -platform-name mydevice -git-branch xlnx_rel_v2022.2 -overlay -compile -out mydevice exit
生成されたpl.dtsiの内容は以下の通りだった。PLのノードがないためにクロックの情報などがかかれたノードがないがこれでいいのか?
/dts-v1/;
/plugin/;
/ {
fragment@0 {
target = <&fpga_full>;
overlay0: __overlay__ {
#address-cells = <2>;
#size-cells = <2>;
firmware-name = "riscv_base_prj.bit.bin";
resets = <&zynqmp_reset 116>,<&zynqmp_reset 117>;
};
};
};
u-dma-buf.koの作成
u-dma-bufを使用するために、petalinuxでカーネルモジュールをビルドする。以下記事を参考にビルドした。
FPGAの部屋 udmabufをPetaLinux 2018.2でビルドする
起動確認
SDカードイメージを書き込んで起動確認をし、u-dma-buf.koを読み込んだ。
xilinx-kv260-starterkit-20221:~$ dmesg | grep cma [ 0.000000] cma: Reserved 512 MiB at 0x0000000057800000 [ 0.000000] Kernel command line: earlycon console=ttyPS1,115200 clk_ignore_unused init_fatal_sh=1 cma=512M uio_pdrv_genirq.of_id=generic-uio [ 0.000000] Memory: 3213632K/4193280K available (14528K kernel code, 1012K rwdata, 4060K rodata, 2176K init, 571K bss, 193216K reserved, 786432K cma-reserved) xilinx-kv260-starterkit-20221:~$ sudo insmod u-dma-buf.ko xilinx-kv260-starterkit-20221:~$ dmesg | grep u-dma-buf [ 117.342056] u-dma-buf udmabuf@40000000: driver probe start. [ 117.342904] u-dma-buf udmabuf@40000000: assigned reserved memory node riscv_buf@40000000 [ 117.405800] u-dma-buf udmabuf0: driver version = 4.0.0 [ 117.405816] u-dma-buf udmabuf0: major number = 237 [ 117.405821] u-dma-buf udmabuf0: minor number = 0 [ 117.405826] u-dma-buf udmabuf0: phys address = 0x0000000040000000 [ 117.405831] u-dma-buf udmabuf0: buffer size = 268435456 [ 117.405838] u-dma-buf udmabuf@40000000: driver installed.
CMA領域が正しく確保されており、u-dma-bufのロードも正しくできているように見える。
VexRiscv動作確認
VexRiscv_Ultra96/test.cpp at dev · lp6m/VexRiscv_Ultra96 · GitHubをベースにudmabufを使用するように修正する。
リセットのGPIOは前回と同じくgpio-172を使用する。
#include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #include <sys/mman.h> #include <sys/stat.h> #include <time.h> #include <stdlib.h> #include <fcntl.h> #include <dirent.h> #include <unistd.h> #include <fcntl.h> #include <cstring> #define REG(address) *(volatile unsigned int*)(address) int pl_resetn_1(){ int fd; char attr[32]; DIR *dir = opendir("/sys/class/gpio/gpio172"); if (!dir) { fd = open("/sys/class/gpio/export", O_WRONLY); if (fd < 0) { perror("open(/sys/class/gpio/export)"); return -1; } strcpy(attr, "172"); write(fd, attr, strlen(attr)); close(fd); dir = opendir("/sys/class/gpio/gpio172"); if (!dir) { return -1; } } closedir(dir); fd = open("/sys/class/gpio/gpio172/direction", O_WRONLY); if (fd < 0) { perror("open(/sys/class/gpio/gpio172/direction)"); return -1; } strcpy(attr, "out"); write(fd, attr, strlen(attr)); close(fd); fd = open("/sys/class/gpio/gpio172/value", O_WRONLY); if (fd < 0) { perror("open(/sys/class/gpio/gpio172/value)"); return -1; } sprintf(attr, "%d", 0); write(fd, attr, strlen(attr)); sprintf(attr, "%d", 1); write(fd, attr, strlen(attr)); close(fd); return 0; } unsigned int float_as_uint(float f){ union {float f; unsigned int i; } union_a; union_a.f = f; return union_a.i; } float uint_as_float(unsigned int i){ union {float f; unsigned int i; } union_a; union_a.i = i; return union_a.f; } // This program is DMEM[0]+DMEM[1]=DMEM[2] int main(){ int fd = open("/dev/udmabuf0", O_RDWR); if (fd < 0) { printf("Device Open Error"); exit(-1); } volatile unsigned int* MEM_BASE = (volatile unsigned int*) mmap(NULL, 0x10000000, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0); //set RISC-V Instruction MEM_BASE[0] = 0x40020437; // 0: lui s0,0x40020000 MEM_BASE[1] = 0x00040413; // 4: mv s0,s0 MEM_BASE[2] = 0x00042607; // 8: flw fa2,0(s0) # 0x40020000 MEM_BASE[3] = 0x00442687; // C: flw fa3,4(s0) MEM_BASE[4] = 0x00c68753; // 10: fadd fa4,fa2,fa3 MEM_BASE[5] = 0x00e42427; // 14: fsw fa4,8(s0) # 0x40020000 MEM_BASE[6] = 0x0000006f; // 18: j 0x18 //TEST start srand(100); int all_ok = 1; for(int i = 0; i < 100; i++){ float a = (rand()%100)/100.0f; float b = (rand()%100)/100.0f; //set input data MEM_BASE[0+4096] = float_as_uint(a); MEM_BASE[1+4096] = float_as_uint(b); //reset to launch RISC-V core pl_resetn_1(); //wait RISC-V execution completion by waiting some period or using polling usleep(100); //get output data unsigned int _c = MEM_BASE[2+4096]; float c = uint_as_float(_c); printf("%f+%f=%f:", a, b, c); if (a + b == c){ printf("OK\n"); } else { printf("NG\n"); all_ok = 0; } } if (all_ok) printf("ALL PASSED\n"); close(fd); return 0; }
全ての結果が0のままでエラーになってしまった。
どこに問題があるのかを考え中。今だにPS/PL間のデータのやり取りの方法やZynqのアーキテクチャを全く理解できていないように思う・・
KV260でVexRiscv動作させた
自分用メモで超手抜き記事です。
rv32imfacアーキテクチャのRISC-Vを動作させる。ARMコアからFPGA上に実装したRISC-Vコアを制御する。
Ultra96-V2で動かすための方法は以下リポジトリに(そこそこ詳しく?)まとめています。ほとんど同じです。
使用するSDイメージ
KV260向けにVitisプラットフォームを作成してDPUを動かす その1 (Vitis 2022.1 + Vitis-AI v2.5) - Qiitaで作ったSDイメージのpetalinuxプロジェクトを基にする。
上記記事のSDイメージではgeneric-uioドライバが有効化されていなかった。後から有効化する方法がよくわからなかったのでとりあえずbootargsを変更して再ビルドしてSDイメージを再生成した。
project-spec/meta-user/recipes-bsp/device-tree/files/system-user.dtsi の修正
bootargsの末尾にuio_pdrv_genirq.of_id=generic-uioを追加
再ビルドしてSDイメージ再生成
petalinux-build petalinux-package --boot --u-boot --force petalinux-package --wic --images-dir images/linux/ --bootfiles "ramdisk.cpio.gz.u-boot,boot.scr,Image,system.dtb,system-zynqmp-sck-kv-g-revB.dtb" --disk-name "mmcblk1"
ブロックデザイン
KV260向けにVitisプラットフォームを作成してDPUを動かす その1 (Vitis 2022.1 + Vitis-AI v2.5) - Qiitaで作ったブロックデザインを元にRISC-Vコアを追加した。

pl_clk1は150MHzに設定した。BRAMのサイズやAXI BRAM Controllerなどに設定するメモリアドレスはUltra96-V2のときと同じにした。
プラットフォームをriscv_base_prj.xsaとして生成した。
binの生成
Ultra96-V2のときはpetalinuxで起動時に書き込まれるビットストリームを RISC-Vのものしていたが、KV260ではデバイスツリーオーバレイを使って起動後にビットストリームを書き込むのが標準(?)らしい。
このため手順が異なる。参考: FPGAの部屋 kv260_median_platform のメディアン・フィルタを KV260 の Petalinux から動作させる14
bootgenを使ってビットストリームをbinに変換する。
mkdir bit
cd bit
cp ../vivado/riscv_base_prj/riscv_base_prj.bit system.bit
echo 'all:{system.bit}'>bootgen.bif
bootgen -w -arch zynqmp -process_bitstream bin -image bootgen.bif
mv system.bit.bin riscv_base_prj.bit.bin
pl.dtsiの生成
デバイスツリーを生成する。
xsct createdts -hw vivado/riscv_base_prj/riscv_base_prj.xsa -zocl -platform-name mydevice -git-branch xlnx_rel_v2022.1 -overlay -compile -out mydevice exit
pl.dtsiの修正
AXI Bram Controllerのデフォルトのドライバはxlnx,axi-bram-ctrl-4.1になっているがgeneric-uioで制御したいのでdtsiファイルを修正する。
mydevice/mydevice/mydevice/psu_cortexa53_0/device_tree_domain/bsp/pl.dtsiを開く
diff pl.dtsi.old ./mydevice/mydevice/mydevice/psu_cortexa53_0/device_tree_domain/bsp/pl.dtsi 54c54 < compatible = "xlnx,axi-bram-ctrl-4.1"; --- > compatible = "generic-uio"; 75c75 < compatible = "xlnx,axi-bram-ctrl-4.1"; --- > compatible = "generic-uio";
pl.dtsiをコンパイルしてdtboの作成
mkdir device_tree dtc -@ -O dtb -o mydevice/mydevice/mydevice/psu_cortexa53_0/device_tree_domain/bsp/pl.dtbo mydevice/mydevice/mydevice/psu_cortexa53_0/device_tree_domain/bsp/pl.dtsi cp mydevice/mydevice/mydevice/psu_cortexa53_0/device_tree_domain/bsp/pl.dtbo device_tree/riscv_base_prj.dtbo
KV260に送るファイルの用意
binファイルとdtboファイル、shell.jsonファイルを1つのディレクトリにまとめる
mkdir riscv_base_prj cp bit/riscv_base_prj.bit.bin riscv_base_prj cp device_tree/riscv_base_prj.dtbo riscv_base_prj touch riscv_base_prj/shell.json
shell.jsonの中身は以下
{
"shell_type" : "XRT_FLAT",
"num_slots": "1"
}KV260に送る
scp -r riscv_base_prj petalinux@192.168.xxx.xxx:~/
KV260でのロード
sudo cp -r riscv_base_prj /lib/firmware/xilinx/ sudo xmutil listapps sudo xmutil unloadapp sudo xmutil loadapp riscv_base_prj
uioを確認すると、uio4, uio5が新たに増えていた。

RISC-Vコア動作確認
VexRiscv_Ultra96/petalinux at dev · lp6m/VexRiscv_Ultra96 · GitHubでも使用した、floatの足し算を行うテストプログラムを実行しようと思う。
test.cppを2点修正する必要がある。
テストプログラムでは100個のfloatの足し算のテストを行うが、1回のテストごとにRISC-Vコア(+ブロックRAMやAXI Interconnectなどすべて)をリセットする。
上で示したブロックデザインの通り、RISC-Vコアのリセットはpl_rstn1に接続されている。これをPSコアから接続するためのGPIOの番号がUltra96-V2の時と異なる。
参考: lp6m.hatenablog.com
KV260でGPIO情報を見ると以下のように表示される。
xilinx-kv260-starterkit-20221:/home/petalinux# cat /sys/kernel/debug/gpio gpiochip1: GPIOs 0-173, parent: platform/ff0a0000.gpio, zynqmp_gpio: gpio-0 (QSPI_CLK ) gpio-1 (QSPI_DQ1 ) gpio-2 (QSPI_DQ2 ) gpio-3 (QSPI_DQ3 ) gpio-4 (QSPI_DQ0 ) gpio-5 (QSPI_CS_B ) gpio-6 (SPI_CLK ) gpio-7 (LED1 |heartbeat ) out lo gpio-8 (LED2 |vbus_det ) out hi
上記ブログ記事を参考にすれば、デバイスに認識されているGPIOの番号がUltra96-V2がgpio-338からgpio-511だったのが、KV260ではgpio-0からgpio-173であることがわかった。(数は同じ174個)
というわけで、pl_rstn1を操作するにはgpio-172を操作すればいい。
下記テストプログラムの510を全て172に変更する。
VexRiscv_Ultra96/test.cpp at dev · lp6m/VexRiscv_Ultra96 · GitHub
また、AXI BRAM Controllerはuio4, uio5として認識されているので、デバイスオープンの/dev/uio0, /dev/uio1を/dev/uio4, /dev/uio5に変更する。
FPU含めて動作完了!

rstan がWindowsで動作しない問題の解決
知り合いから頼まれたので備忘録。Rなんて使うことない気がしますが。
- R-4.2.0 for Windows
- R Tools 4.2.0
- R Studio Desktop
- rstan
qiita.com
こちらの記事を参考に、RStanをインストール、サンプルを実行すると以下のエラーで落ちる。
> x <- rbinom(n = 100, size = 20, prob = 0.8)
> binomial_test <- "
+ data {
+ int N;
+ int n;
+ int x[n];
+ }
+ parameters {
+ real<lower=0, upper=1> p;
+ }
+ model {
+ x ~ binomial(N, p);
+ } "
> d <- list(N = 20, x = x, n = length(x))
> fit <- stan(
+ model_code = binomial_test ,
+ data= d)
make cmd is
make -f "C:/PROGRA~1/R/R-42~1.0/etc/x64/Makeconf" -f "C:/PROGRA~1/R/R-42~1.0/share/make/winshlib.mk" CXX='$(CXX14) $(CXX14STD)' CXXFLAGS='$(CXX14FLAGS)' CXXPICFLAGS='$(CXX14PICFLAGS)' SHLIB_LDFLAGS='$(SHLIB_CXX14LDFLAGS)' SHLIB_LD='$(SHLIB_CXX14LD)' SHLIB="file131459b7778.dll" WIN=64 TCLBIN= OBJECTS="file131459b7778.o"
make would use
if test "zfile131459b7778.o" != "z"; then \
if test -e "file131459b7778-win.def"; then \
echo g++ -shared -s -static-libgcc -o file131459b7778.dll file131459b7778-win.def file131459b7778.o -L"C:/rtools42/x86_64-w64-mingw32.static.posix/lib/x64" -L"C:/rtools42/x86_64-w64-mingw32.static.posix/lib" -L"C:/PROGRA~1/R/R-42~1.0/bin/x64" -lR ; \
g++ -shared -s -static-libgcc -o file131459b7778.dll file131459b7778-win.def file131459b7778.o -L"C:/rtools42/x86_64-w64-mingw32.static.posix/lib/x64" -L"C:/rtools42/x86_64-w64-mingw32.static.posix/lib" -L"C:/PROGRA~1/R/R-42~1.0/bin/x64" -lR ; \
else \
echo EXPORTS > tmp.def; \
nm file131459b7778.o | sed -n 's/^.* [BCDRT] / /p' | sed -e '/[.]refptr[.]/d' -e '/[.]weak[.]/d' | sed 's/[^ ][^ ]*/"&"/g' >> tmp.def; \
echo g++ -shared -s -static-libgcc -o file131459b7778.dll tmp.def file131459b7778.o -L"C:/rtools42/x86_64-w64-mingw32.static.posix/lib/x64" -L"C:/rtools42/x86_64-w64-mingw32.static.posix/lib" -L"C:/PROGRA~1/R/R-42~1.0/bin/x64" -lR ; \
g++ -shared -s -static-libgcc -o file131459b7778.dll tmp.def file131459b7778.o -L"C:/rtools42/x86_64-w64-mingw32.static.posix/lib/x64" -L"C:/rtools42/x86_64-w64-mingw32.static.posix/lib" -L"C:/PROGRA~1/R/R-42~1.0/bin/x64" -lR ; \
rm -f tmp.def; \
fi \
fi
Error in compileCode(f, code, language = language, verbose = verbose) :
C:\rtools42\x86_64-w64-mingw32.static.posix\bin/ld.exe: file131459b7778.o:file131459b7778.cpp:(.text$_ZN3tbb8internal26task_scheduler_observer_v3D0Ev[_ZN3tbb8internal26task_scheduler_observer_v3D0Ev]+0x1d): undefined reference to `tbb::internal::task_scheduler_observer_v3::observe(bool)'C:\rtools42\x86_64-w64-mingw32.static.posix\bin/ld.exe: file131459b7778.o:file131459b7778.cpp:(.text$_ZN3tbb10interface623task_scheduler_observerD1Ev[_ZN3tbb10interface623task_scheduler_observerD1Ev]+0x1d): undefined reference to `tbb::internal::task_scheduler_observer_v3::observe(bool)'C:\rtools42\x86_64-w64-mingw32.static.posix\bin/ld.exe: file131459b7778.o:file131459b7778.cpp:(.text$_ZN3tbb10interface623task_scheduler_observerD1Ev[_ZN3tbb10interface623task_scheduler_observerD1Ev]+0x3a): undefined reference to `tbb::internal::task_scheduler_observer_v3::observe(bool)'C:\rtools42\x86_64-w64-mingw32.static.posix\bin/ld.exe: file131459b7778.o:file131459b7778.cpp:(.text$_ZN3tbb10interface623task_
Error in sink(type = "output") : invalid connection色々調べてると以下の情報を得た。
Error running Stan Model with rstan 2.21 and R 4.0.2 - RStan - The Stan Forums
As you all have noticed, there are a large number of people who are having problems with rstan 2.21.x on Windows.
というわけでrstanのバージョンを下げればとりあえず動く。
Rstanのバージョン一覧で2.21より前の最新は2.19.3なのでこれを入れる。
Index of /src/contrib/Archive/rstan
古いバージョンのインストール方法の参考:
https://support.rstudio.com/hc/en-us/articles/219949047-Installing-older-versions-of-packages
packageVersion("rstan") //2.21.3が入っていることを確認
detach("package:rstan", unload=TRUE) //アンロード
install.packages("devtools")
require(devtools)
install_version("rstan", version = "2.19.3", repos = "http://cran.us.r-project.org")
library(rstan)
packageVersion("rstan") //2.19.3を確認rstan 2.19.3をインストールした後はRstudioを再起動しないとうまく動作しなかった。
Rstudioを再起動してから再度Qiitaの記事のコードを実行すると問題なく動いた。
Makevars.winなどの修正はなしでとりあえず動いた。
第5回AIエッジコンテストに参加した感想
経産省主催の第5回AIエッジコンテストにチームVerticalBeachとして参加しました。開発したリポジトリの整理などは後ほど行う予定です。
参加した感想を忘れないうちに所感を残しておこうと思います。
詳細な技術情報は提出した以下のレポートに記載しています。
drive.google.com
コンテスト概要
最終結果
物体検出はそこそこできているが、物体追跡が甘い。MOTA=0.2807344
1フレームあたりの速度:52.30ms (18fps程度は出そう?)
上が物体検出結果、下が物体追跡結果です。
youtu.be
前回の第4回AIエッジコンテストでは、自分のチーム含め処理速度入賞者の全員がXilinx DPUを使っていて、ほとんどDPUコンテストと化していた。
それを受けてか今回はRISCVコアをFPGA上に実装することが必須条件であり、実装ハードルが高いことは最初からわかっていた。
コンテストの開催期間は4ヶ月で、RISCVの実装経験もなかったのでできるだけ既存の実装を使って、とにかく何が何でも提出する、ということを目標にした。
題材自体はHW実装なしの第3回AIエッジコンテストと同じで、第3回の入賞者レポートを見る限り、MOTA>0.6という精度指標をエッジデバイスでリアルタイム性能を出しながら満たすのは非常に厳しいと思った。
前回のコンテストでXilinx DPUとVitis-AIを使用した経験があったので、物体検出(DPU)+物体追跡(RISCV)の組み合わせで実装することにした。(DNNモデルを動かすためのRISCV追加命令の実装!とかは確実に間に合わなそうだったので)
10月・11月
DPUで動作する物体検出モデルを選定する必要があるが、tinyYOLOv3が動作することは知っていたので、精度が向上したtinyYOLOv4を使用してみることにした。
DarknetからCaffeに変換するスクリプトを修正することで、DPUにオフロードされるsubgraphが1個にできた。経験もあったので特に難しいことはなかった。
前回コンテストではAvnetが用意してくれたHW環境をそのまま使っていたので、HW側の設計はほとんどせず、ただDPUを触っていただけだった。
今回はDPUだけでなくRISCVを搭載する必要があったので、自分でHW環境をビルドする必要があった。前回何も理解していなかったVitisフローを勉強した。 DPUとvector addカーネルの両方を乗せることができた。
Ultra96v2のWIFIを動かすために無駄な時間を食ってしまったが、結局最終的なHW環境ではWIFIは使用せずにUSB-LANを使用することにした。
qiita.com
12月
11/30にコンテスト主催側からRISCVのリファレンス環境が公開された。VexRiscvというRISCV実装が使用されていた。公開されるまではRocketChipを使うかVexRISCVを使うか、あるいはRISC-VとChiselで学ぶ はじめてのCPU自作を使うか迷っていた。
RocketChipはFPGAでは動作周波数が低いことや、リファレンス環境を流用できることからVexRiscvを使用することにした。
GitHub - SpinalHDL/VexRiscv: A FPGA friendly 32 bit RISC-V CPU implementation
リファレンス環境はベアメタルでの動作確認のみだったので、Petalinuxから実行できるか実験した。
qiita.com
ただ、このリファレンス環境には問題があることがわかった。RISCVコアのリセットがGPIO経由で行われていたが、命令バス・データバスのリセットは別で接続されていたので、2回目のリセット以降正常に計算が行われないことがわかった。
RISCVコアのリセットをpl_resetn0に接続して、PS側から制御する方法を学んだ。
lp6m.hatenablog.com
次に、リファレンス実装のRISCVの命令セットはrv32imで、浮動小数点演算が行えないので困った。VexRiscvではプラグインを追加する形でFPUを載せられるので、追加した。
ただ、リファレンス実装ではRISCVコアの命令バス・データバスをAXIバスに接続するために独自モジュールを使っていて、FPUを乗せると命令バスとデータバスのポート数が変わるために独自モジュールが使えなくなり頭を抱えた。
よく見てみるとVexRiscv自体に命令バス・データバスをAXI化する機能があったのでこれを使うことで問題は解決した。(なぜリファレンス実装は独自モジュールを使っていたのか・・)
手順は今後公開する予定です。
年末年始にFPUが動いて嬉しかった。
FPU動いた pic.twitter.com/gKR7XN2IgI
— lp6m (@lp6m1) December 31, 2021
1月
FPUを搭載したRISCV向けにクロスコンパイルする手法を調べた。cross-ngを使ってクロスコンパイルができることがわかった。RISCVとPSコア間のデータの入出力を実現するのに少しだけリンカスクリプトの勉強をした。
11月に勉強したVitisフローを使ってRISCVとDPUを両方搭載したHW環境を作ることができた。
チームメイトが物体追跡アルゴリズムの勉強・実装調査をしてくれていたので物体追跡はByteTrackを使用することにした。
ByteTrackはReIDモデルを使用しない単純なアルゴリズムにもかかわらずSOTAを実現しているので、何もわかっていないけど期待感だけあった。
GitHub - ifzhang/ByteTrack: ByteTrack: Multi-Object Tracking by Associating Every Detection Box
ByteTrackをそのまま適用したが、MOTAスコアは0.17程度で0.60には遥か遠く希望を失った。
今回物体追跡アルゴリズムについては自分は担当していないので詳しいことはわかっていないが、コンテストのテスト動画のフレームレートが5fpsで、1フレームごとにバウンディングボックスの移動量が非常に大きいのでカルマンフィルタによるバウンディングボックスの位置推定が非常に厳しいようだった。
DPUでの物体検出結果をチームメイトに渡して、チームメイトにはそれをもとにByteTrackの改善をしてもらっていた。チームメイトが開発してくれていたC++製のByteTrackがUltra96のARMコア上で動作することを確認した。
Ultra96のPetalinuxでインストールされていたOpenCVがmp4を開けなかったり(aviに変換して解決)、cv::VideoCaptureがメモリリークを起こしたりしていて(1動画ずつ処理して回避)、厳しかった。
2月
2月に入ってもまだRISCVコアで何を動作させるか決まっていなかった。ByteTrackで使用されているハンガリアン法のアルゴリズムが簡単にRISCV向けにクロスコンパイルできそうということで、これをRISCVで動作させることにした。クロスコンパイルするとRISCVのデータメモリが当初の大きさだと足りないことがわかって、Vitisフローを1からやり直してデータメモリを大きくした。厳しかった。
すべてARMコアで動作させていたByteTrackのソースを改変してDPUとRISCVを使用するようにした。
物体検出と物体追跡処理のマルチスレッド化を実装して、
チームメイトはギリギリまでByteTrackの改善をしてくれて、最終的に評価値は0.2807344まで改善した!感謝。
レポートを書いたり実機評価をして、提出締め切りギリギリに提出した。
提出者が少なかったせいか提出期限が伸びたので、YOLOv4tinyの入力画像サイズを大きくするなどしたが、MOTAが改善することはなかった。
とりあえず提出するという当初の目標は達成できたが、ほとんどVitisフローとVexRiscvの実装方法の勉強に費やしてしまっていた。前回のコンテストもVitis-AIについて学んでいただけだった・・
RISCVの実装・命令の拡張にチャレンジするという余裕は全くなかった・・
上には厳しい気持ちになったとたくさん書いたが、こういった実装コンテストのおかげで色々学べるのはやっぱり楽しかった。
HLSでDNNモデルをHW実装するコンテストがあれば、(少なくとも自分は)VivadoやVitisの使い方を学ぶ時間は少なくてすむので、HW実装に注力できて面白そうだと思った。
Ultra96v2のpl_resetnxをPSから制御
Qiitaとの記事の分け方が微妙だが、雑に書くのはこちらで書こうと思う。
Ultra96v2のPSコアからはpl_resetn0, pl_resetn1, pl_resetn2, pl_resetn3の4つのリセットがある。これをPSから制御したい。
以下のリンクを見るだけで理解できる人は理解できると思うが、よくわからなかったので実践した。
- AR# 68962: Zynq MPSoC PS pl_resetnx ポートの制御アドレスの取得方法
https://support.xilinx.com/s/article/68962?language=ja
ブロックデザインの作成
リセットされているかを目で確認したかったのでLチカモジュールを作成した。
AXI BRAMとBRAM Generatorがブロックデザインには含まれているが今回は関係ないので不要。
- ブロックデザイン
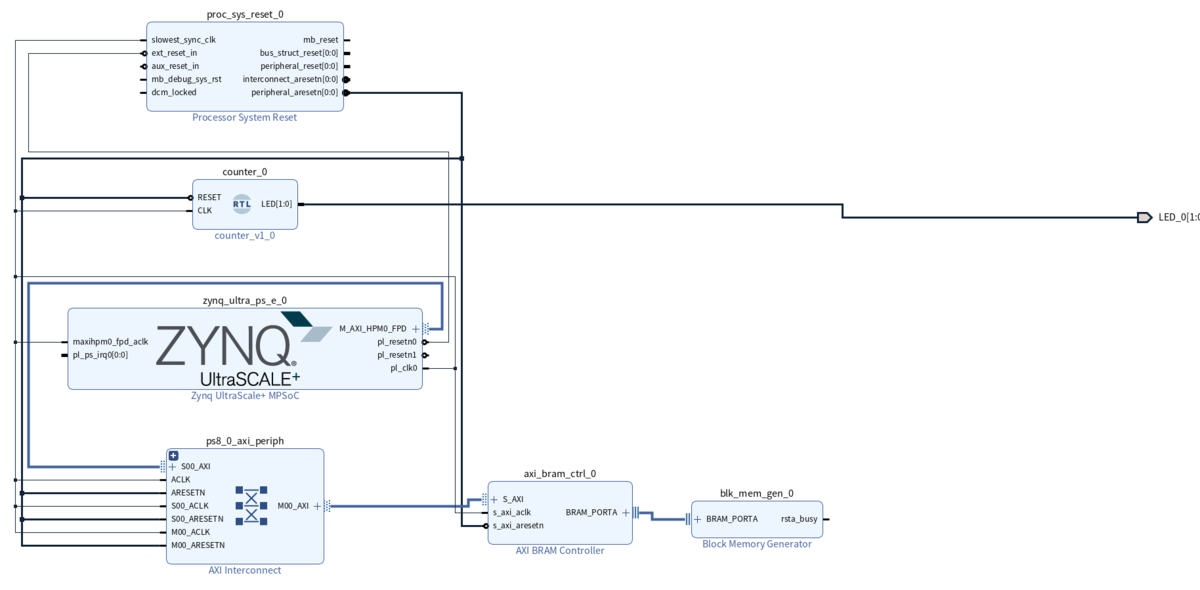
- Lチカモジュール
リセットがかかると一定時間2つのLEDが点灯し、その後2つのLEDは交互に点灯する。
gist.github.com
- 制約ファイル
PL側に接続されているLEDを出力ピンに割り当てる。
set_property PACKAGE_PIN A9 [get_ports {LED_0[0]}]
set_property PACKAGE_PIN B9 [get_ports {LED_0[1]}]
set_property IOSTANDARD LVCMOS18 [get_ports {LED_0[0]}]
set_property IOSTANDARD LVCMOS18 [get_ports {LED_0[1]}]Write Bitstream -> Export Hardware (Include Bitstream)でVivadoでの作業は完了
ベアメタルでの制御
VivadoからLaunch Vitis IDEでVitis IDEを起動、Application Projectを新規作成、VivadoでエクスポートしたXSAを選択してHello Worldテンプレートを選択
ここから先述のAR同様、pl_resetn0を制御するための制御アドレスを調べていく。
- ZynqMP Ultrascale テクニカルリファレンスマニュアル
https://japan.xilinx.com/support/documentation/user_guides/j_ug1085-zynq-ultrascale-trm.pdf
このリファレンスマニュアルの607ページの図を見ると、pl_resetn0であるEMIO[95]はGPIO Bank 5に属していることがわかる。
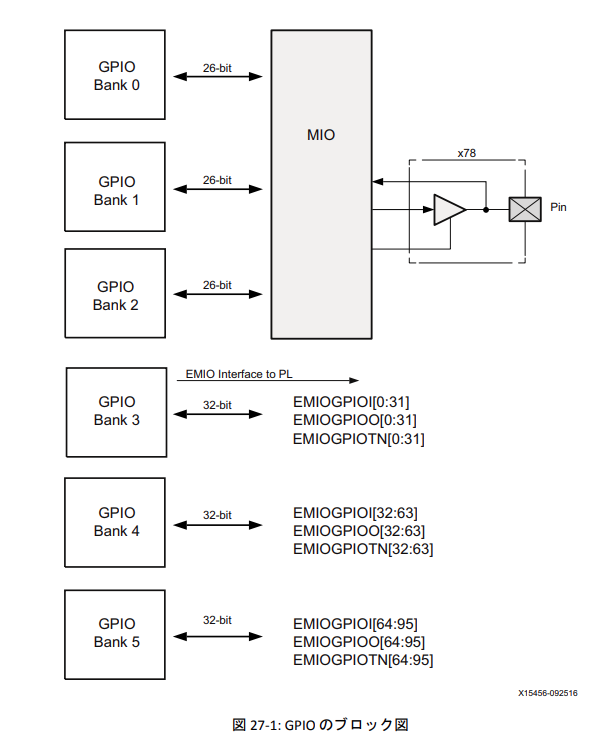
psu_init.c, psu_init.hファイルから、GPIO_DIRM_5_OFFSET, GPIO_OEN_5_OFFSET, GPIO_DATA_5_OFFSETの3つの物理アドレスを入手する。
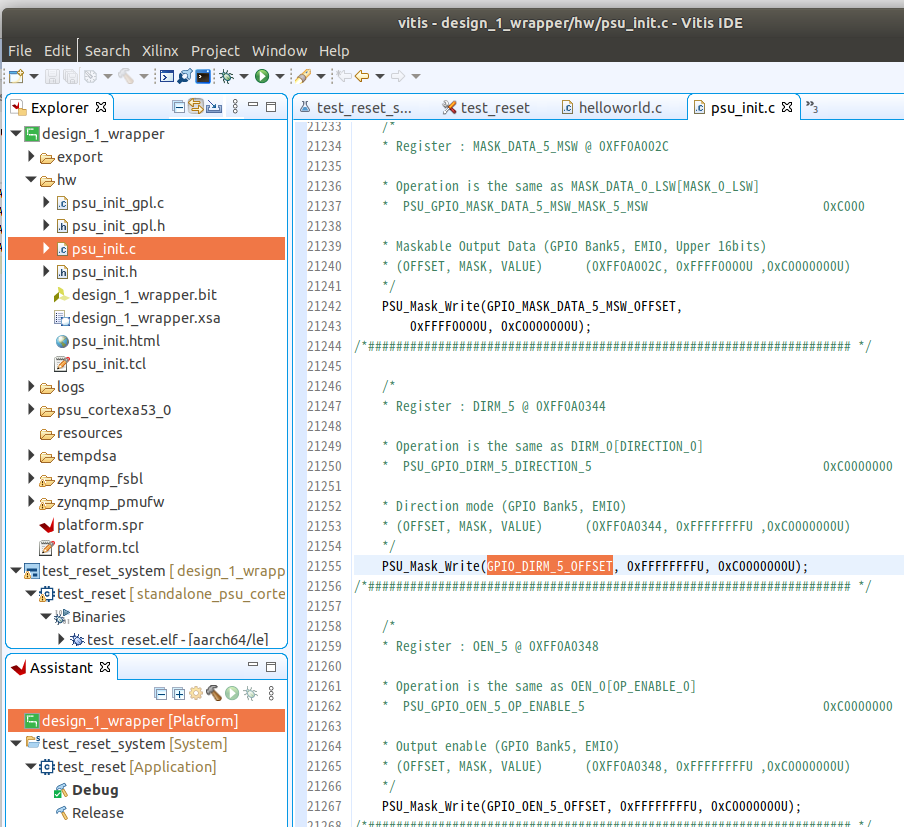
このアドレスを制御すればリセットがかけられるということになる。GPIOの制御はこちらの記事を参考にした。ありがとうございます。
qiita.com
記事ではXilinxから提供されるGPIO用ライブラリXGpioを使った例も紹介されているが、今回はレジスタを直接叩く。
テンプレートから作成されたhelloworld.cを以下のように書き換える。
gist.github.com
Reset Now!!が表示されるとともに2つのLEDが光って、きちんとリセット制御ができることを確認した。
Petalinuxでの制御
プロジェクトは、下記記事を参考に作ればOK。
RISC-VをUltra96上のpetalinuxから実行 - Qiita
system-user.dtsiは下記のようにした。
/include/ "system-conf.dtsi"
/ {
chosen {
bootargs = "earlycon console=ttyPS0,115200 clk_ignore_unused root=/dev/mmcblk0p2 rw rootwait cma=512M uio_pdrv_genirq.of_id=generic-uio";
};
xlnk {
compatible = "xlnx,xlnk-1.0";
};
};
&sdhci0 {
disable-wp;
};デフォルトでPetalinuxがXilinx製のGPIO/EMIO制御のドライバを使うようになっているので、これを使用する。GPIOの情報は下記コマンドで確認できる。
cat /sys/kernel/debug/gpio gpiochip0: GPIOs 338-511, parent: platform/ff0a0000.gpio, zynqmp_gpio: gpio-338 (UART1_TX ) gpio-339 (UART1_RX ) gpio-340 (UART0_RX ) gpio-341 (UART0_TX ) gpio-342 (I2C1_SCL ) gpio-343 (I2C1_SDA ) ... gpio-511 ( )
gpio-338からgpio-511まで、511-338+1=174個ある。これは上記テクニカルリファレンスマニュアルのGPIOのピン情報(26x3+32*3=174)と一致する。すなわちpl_resetn0が繋がっているEMIO95を操作するには、gpio-511を操作すればよいということがわかった。
というわけで、petalinuxから下記コマンドでリセット操作が行える。
echo 511 > /sys/class/gpio/export echo out > /sys/class/gpio/gpio511/direction echo 0 > /sys/class/gpio/gpio511/value echo 1 > /sys/class/gpio/gpio511/value
ちなみに、このGPIOのドライバがどのように適用されているかを確認してみた。petalinux-buildで生成された統合されたデバイスツリーファイル(system.dtb)をデコンパイルして見ればわかる。
cd <petalinux_project_directory> cd images/linux dtc -I dtb -O dts -o system.dts sytem.dtb
system.dtbにGPIO/EMIO用のデバイスツリー記述を見つけた。
gpio@ff0a0000 {
compatible = "xlnx,zynqmp-gpio-1.0";
status = "okay";
#gpio-cells = <0x2>;
gpio-controller;
interrupt-parent = <0x4>;
interrupts = <0x0 0x10 0x4>;
interrupt-controller;
#interrupt-cells = <0x2>;
reg = <0x0 0xff0a0000 0x0 0x1000>;
power-domains = <0xc 0x2e>;
clocks = <0x3 0x1f>;
emio-gpio-width = <0x20>;
gpio-mask-high = <0x0>;
gpio-mask-low = <0x5600>;
gpio-line-names = "UART1_TX", "UART1_RX", "UART0_RX", "UART0_TX", "I2C1_SCL", "I2C1_SDA", "SPI1_SCLK", "WLAN_EN", "BT_EN", "SPI1_CS", "SPI1_MISO", "SPI1_MOSI", "I2C_MUX_RESET", "SD0_DAT0", "SD0_DAT1", "SD0_DAT2", "SD0_DAT3", "PS_LED3", "PS_LED2", "PS_LED1", "PS_LED0", "SD0_CMD", "SD0_CLK", "GPIO_PB", "SD0_DETECT", "VBUS_DET", "POWER_INT", "DP_AUX", "DP_HPD", "DP_OE", "DP_AUX_IN", "INA226_ALERT", "PS_FP_PWR_EN", "PL_PWR_EN", "POWER_KILL", "", "GPIO-A", "GPIO-B", "SPI0_SCLK", "GPIO-C", "GPIO-D", "SPI0_CS", "SPI0_MISO", "SPI_MOSI", "GPIO-E", "GPIO-F", "SD1_D0", "SD1_D1", "SD1_D2", "SD1_D3", "SD1_CMD", "SD1_CLK", "USB0_CLK", "USB0_DIR", "USB0_DATA2", "USB0_NXT", "USB0_DATA0", "USB0_DATA1", "USB0_STP", "USB0_DATA3", "USB0_DATA4", "USB0_DATA5", "USB0_DATA6", "USB0_DATA7", "USB1_CLK", "USB1_DIR", "USB1_DATA2", "USB1_NXT", "USB1_DATA0", "USB1_DATA1", "USB1_STP", "USB1_DATA3", "USB1_DATA4", "USB1_DATA5", "USB1_DATA6", "USB_DATA7", "WLAN_IRQ", "PMIC_IRQ", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "";
phandle = <0x10>;
};gpio-line-namesのところを上書きすれば/sys/kernel/debug/gpioを見たときにわかりやすいラベルが付けられるんだなと思った。
おしまい
家のWindowsマシンにVPSとポートフォワーディングを使用してリモートデスクトップアクセス
前回はUbuntuだったしSSHさえつながれば良かったが今回はRDP(リモートデスクトップ)を使って接続する。
何
- 家のWindowsサーバは世界に公開したくない
- さくらVPSをレンタルしている
- 家のWindowsデスクトップに外からリモートデスクトップアクセスをしたい
うまくいかないので勘でやっていた。
sshだけなら片方向からトンネルを貼ればいけたが、今回は両方向からトンネルをはらないといけないのかなと思っていた。
結局自力じゃうまくできなかったので頑張ってググった。状況が違う(sshサーバとwindowsサーバがローカルでつながっている等)の例が多くて検索が大変だった。
qiita.com
上に詳しいことは書かれていた。
家のGPUマシンにVPSとポートフォワーディングを使用してリモートアクセス + リモート上のdockerコンテナにVSCodeでアタッチ
環境
ポートフォワーディングの設定
とりあえず家のGPUマシンにssh接続できるようにする。参考リンクを参考にすればできる。
ネットワークの知識がホットミルクの膜くらい薄い僕が、リモートアクセスしたという話|森田 拓朗|note
SSHポートフォワード(トンネリング)を使って、遠隔地からLAN内のコンピュータにログインする - 2014-09-12 - ククログ
VPSを経由して安全に自宅サーバを公開する - Qiita
GPUマシン側で以下を実行
vps_usernameはVPS上のubuntuユーザ名、vps_addressはVPSのグローバルIP、192.168.xx.yyはGPUマシンのローカルIPを設定する。
ssh <vps_username>@<vps_address>-R 10022:192.168.xx.yy:22
ssh接続はしばらくするとタイムアウトするので適宜設定する。めんどくさかったらtopを実行しておけば切れない。
vpsのsshポートがデフォルトじゃない場合は適宜修正。
クライアント側からアクセス
ssh <vps_username>@<vps_address> ssh <gpu_username>@localhost -p 10022
これでアクセスできる!
dockerコンテナへアタッチ
VSCodeのremote developmentでdockerコンテナにアタッチしたいが、ポートフォワーディングしているせいか?うまくできなかった。
単純にsshしているリモートマシンで動作しているdockerコンテナへのアタッチは特に何の設定もせずにできるが、よくわからなかったので以下の方法を参考にした。
※ローカルマシン側にdocker環境をいれておかないとそもそもVSCodeのdocker remote developmentが使えないのでいれておく。
リモートサーバーの中のDockerにローカルから接続する - Eospedia
ssh -fNL localhost:23750:/var/run/docker.sock <gpu_username>@tokyogpu export DOCKER_HOST=localhost:23750 code
とりあえずこれで直接アタッチできるようになった。
よくわからなかった部分をいつか理解したいが・・