Vivado HLSでRGB/HSV + HOG + SVMの高速物体検出をする2(完成)
前回(Vivado HLSでHOG+SVMの高速物体検出をする1(2つめのコンポーネントまで作成) - lp6m’s blog)の続き。
(相変わらず時間がすごくたってしまったけど)
何をつくったのか
ココにHLSプロジェクト・Vivadoプロジェクト・DeviceTreeなど全ておいています。とりあえずの使い方などはREADMEに書きました。
Python3+scikit-learnでLinear SVMの学習を行う。学習したパラメータを取り出して、C++に推論のコードを移植。その後推論コードをFPGA向けのアルゴリズムを使ってHLS IPを作成。
SWのみで実行した場合よりも270倍以上高速化された!!
github.com
このプロジェクトはHEART 2019 Design Contestのために開発しました。
コンテストで赤信号を検出して停止する様子:
www.youtube.com
仕様
作成したHLS IPの最終的な仕様は以下のようになった。
- スライディングウインドウ法 * SVMで物体検出
- 入力:320pix*240pix BGR画像(1画素32bit, 8bit不使用)((OpenCVではデフォルトがRGBではなくBGRの順。24bitでなく32bitにしているのは転送に使用するDMAが2のべき乗のデータ幅しか使えないため)
- ウインドウサイズ:32pix*64pix
- 出力:891個のウインドウ領域に対するSVMの出力
- 特徴量:HOG(Histogram of Oriented Gradients)・BGR,HSV画素値
基本的なアルゴリズムは参照している論文の通り。これにBGR/HSV特徴量を追加した。
HOGについてはセルサイズ8pix, ブロックサイズ2*2,ヒストグラムのビン数9で論文と同様。
BGR/HSV画素特徴量に関しては以前のRFのとき(FPGAデザインコンテスト@FPT2018 開発記 - lp6m’s blog)同様、32pix*64pix画像を8*8に圧縮したものを使用する。
参照した論文との仕様の違い
HLS IP全体像
作成したHLS IPには以下の図のような構成になっており、トップファンクションから呼ばれる関数が6つある(最後のmergeはトップファンクション内に書いている)。
画像の左部分がHOG, 右部分がBGRHSVの特徴量に対する処理となっている。左部分の4つの関数は論文を参考に実装したもの。
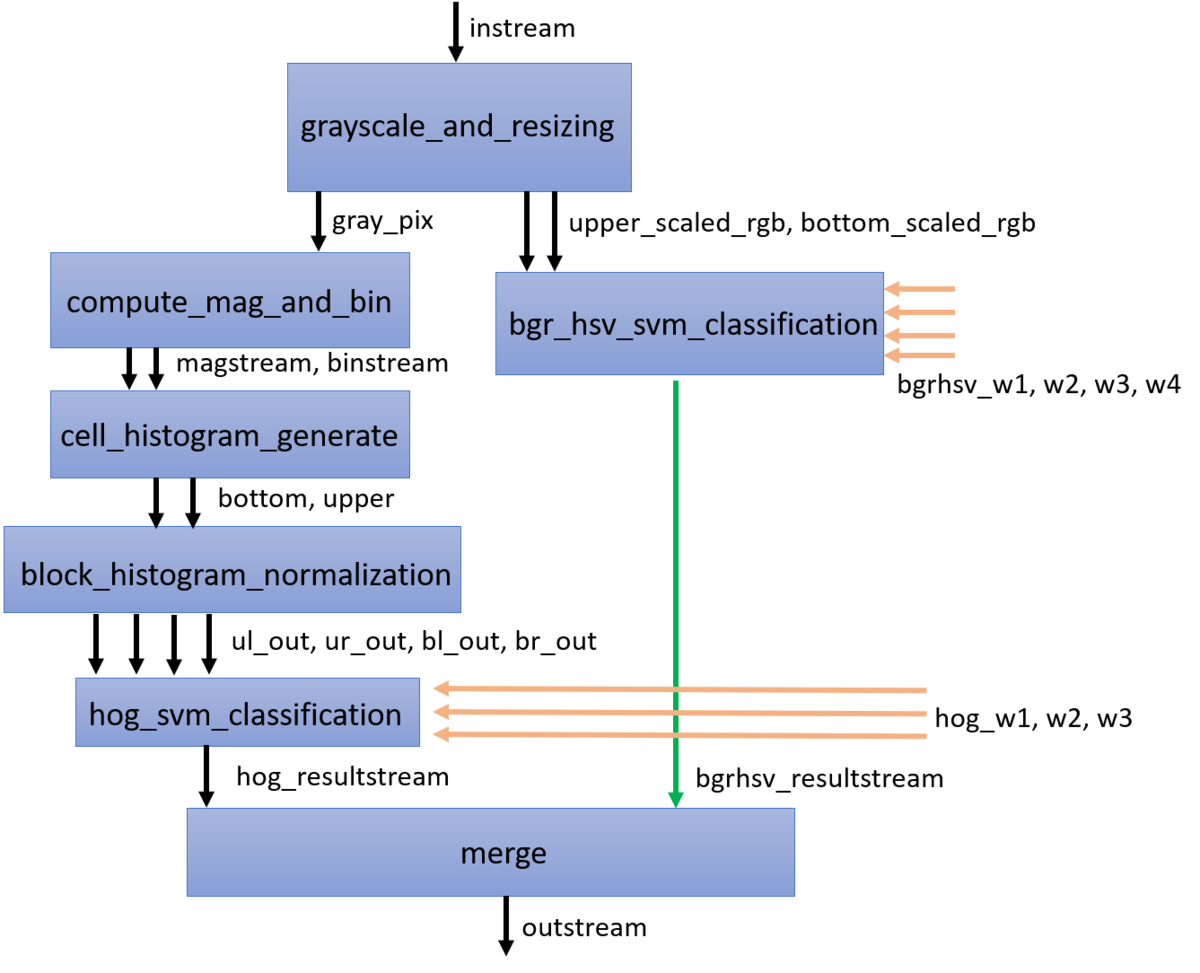
オレンジ色の矢印は外部BRAMからのSVMの重みを表す。
関数間のFIFOは#pragma HLS DATAFLOWを使えばVivado HLSが適切にFIFOを設定してくれるが、関数のバイパスには対応しておらず、緑の矢印部分にはFIFOが挿入されない。
左部分のHOG部分と右部分のBGRHSV部分では、値がでてくるまでのレイテンシが異なるので、FIFOを挿入する必要がある。
このため、#pragma HLS STREAM variable = bgr_hsv_resultstream depth = 100 dim = 1で明示的にFIFOを挿入している。
前回の記事時点ではcompute_mag_and_binとcell_histogram_generateを作成しただけだった。
HOG部分は基本的には論文そのまま実装しているので省略。何故か論文の図にはFIFOとかBRAMとだけ書いててどのようなアクセスをするのかが書いていなかったりして理解するのに少し時間がかかった。
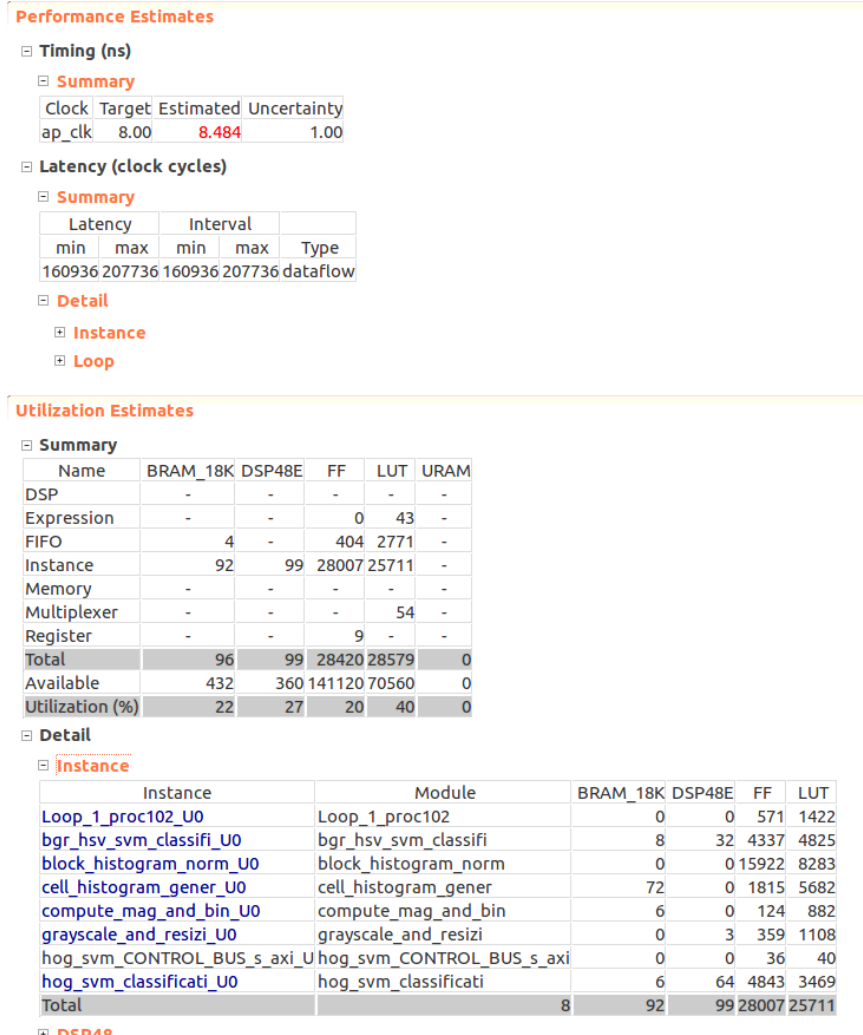
HLS高位合成結果
合成結果は以下の通り。レイテンシがmin:160936, max:207736となっている。1画素に対して207736/320/240=2.7クロック程度かかる計算になる。ループのパイプライン化が完全にできていないところが何箇所かあるが、回路面積との兼ね合いでこのような結果になった。
回路面積を減らすために積算・除算のところに#pragma HLS allocation instances= limit=2を挿入している。
制約は8nsで合成結果は8.48snsになっているが、100MHzのクロックしか刺さないので問題ないとした。
Vivadoブロックデザイン

作成したHLS IPをDMA経由でZynq PSと接続する。
HLS IPのBRAMからの重み入力にはBlock Memory Generatorと接続する。Block Memory GeneratorとAXI BRAM Controllerを接続し、AXI BRAM ControllerをAXI Interconnect経由で接続することでBRAMの値をPSから読み書きできる。 参考:VIVADO HLS Training - BRAM interface #06 - YouTube
DMAをカスタマイズする部分としては以下の通り。
- シンプルモードしか使用しないのでEnable Scatter Gather Engineをオフ
- Width of Buffer Length Registerを21にする(データ転送量が320*240*32+891*32bit < 2^21のため)参考:FPGA+SoC+LinuxでXilinx AXI DMAを試す — ふがふが
HLS IPの動作周波数は100MHzとした。
回路を合成した結果、タイミングエラーはなかった。
Ultra96へのOSインストール・Device Tree Overlay
Ultra96での実機動作のためのアレコレには、こちらのリンクを大変参考にさせていただきました。ありがとうございます。
qiita.com
proc-cpuinfo.fixstars.com
また、udmabufを使用したDMA制御のサンプルに、Interface1月号の「最強FPGAボードで人工知能カリカリ画像認識」を大変参考にさせていただきました。ありがとうございます。
shop.cqpub.co.jp
LinuxからFPGA上のIPコアを制御するための簡単な説明を書くと(嘘を書いていたら指摘して下さい)、FPGA IPの制御のためのレジスタはメモリマップされており、指定のアドレス(アドレスはAddress Editorで見れる)を制御することでFPGA IPを制御することができる。
一番単純なのはdevmemコマンドで物理アドレスを指定して直接レジスタを制御する方法で、C言語だとmmapして仮想アドレスを取得し、そのアドレスに値を書き込むことで実現できる。ただ物理アドレスを直接指定して制御するのは、OS等が使用しているメモリを破壊する可能性があり危険なので、デバイスドライバを記述するのがよいとされる。(udmabufはコレ!)xilinxのvideo系のデバイスドライバはこの辺にあったりする(ドキュメントとか例が全然ない!)。
ただ自作のIP(今回はHLS IP)ごとにデバイスドライバを作成するのも面倒なので実験段階ではUIOという仕組みを使用することが多い。デバイスツリー*1にgeneric-uioと記述し、使用するアドレスの範囲を記述する。これで比較的簡単・安全にIPを制御することができる。デバイスツリーによりLinux OSにはUIOデバイスとして/dev/uio に登録される。プログラムからは/dev/uioをopenしてからmmapして仮想アドレスを取得する。
これまではLinuxカーネルイメージの作成にPetaLinuxを使用していた。カーネルイメージを作成する際にデバイスツリーを使用していたので、回路を変更する度にカーネルイメージをビルドする必要があった。
今回からは最近流行り(?)のLinuxカーネルのDevice Tree Overlayという機能を使用することで、実機からFPGAのコンフィグレーション・デバイスツリーのオーバレイができるようになった!参考:FPGA+SoC+LinuxでDevice Tree Overlayを試してみた - Qiita
注意点としては、udmabufのためのDeviceTreeファイル(udmabuf0.dts, udmabuf1.dts)に記載するバッファサイズを余裕をもって大きく設定した際、合計が2^21(Vivadoで設定したDMAのWidth of Buffer Length Registerの値)を超えないようにすること。
当たり前ですが、ハマってしまったので。
IFレイヤー・アプリケーションの作成・性能評価
まずgithubに公開したapp/hog_svm_testについて説明する。
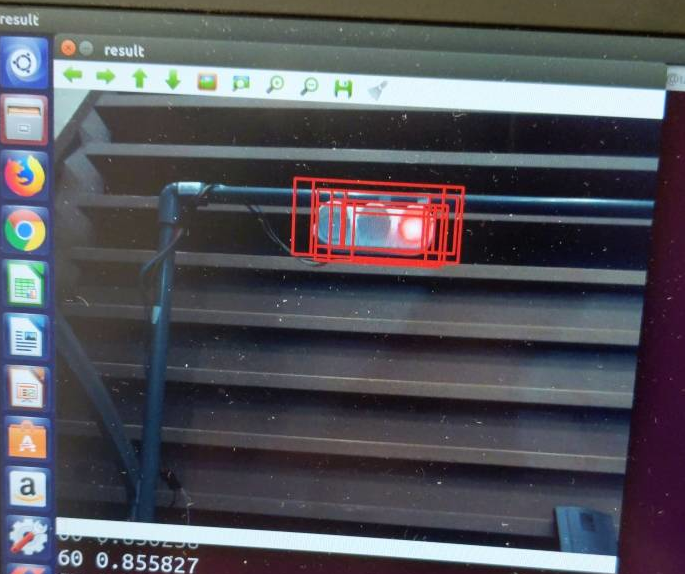
このアプリケーションは320pix*240pixのframe.pngから赤信号を検出し、検出結果をresult.pngに保存する。
result.pngはこんな感じになる。赤信号が正しく検出されていることが確認できる。

SVMの重みはweights.jsonに保存されている。これを読み込んで、BRAMに書き込む。その後DMAで入力画像を転送・結果を転送している。
app/hog_svm_test/main.cppの51,52行目の
regs_write32(hls_regs, 0x01); //start regs_write32(hls_regs, 0x80); //enable autorestart
はVivado HLSで合成時に自動生成されるドライバファイル、hls/hog_svm/solution1/impl/ip/drivers/hog_svm_v1_0/src/xhog.svm.c内の
void XHog_svm_Start(XHog_svm *InstancePtr) { u32 Data; Xil_AssertVoid(InstancePtr != NULL); Xil_AssertVoid(InstancePtr->IsReady == XIL_COMPONENT_IS_READY); Data = XHog_svm_ReadReg(InstancePtr->Control_bus_BaseAddress, XHOG_SVM_CONTROL_BUS_ADDR_AP_CTRL) & 0x80; XHog_svm_WriteReg(InstancePtr->Control_bus_BaseAddress, XHOG_SVM_CONTROL_BUS_ADDR_AP_CTRL, Data | 0x01); } void XHog_svm_EnableAutoRestart(XHog_svm *InstancePtr) { Xil_AssertVoid(InstancePtr != NULL); Xil_AssertVoid(InstancePtr->IsReady == XIL_COMPONENT_IS_READY); XHog_svm_WriteReg(InstancePtr->Control_bus_BaseAddress, XHOG_SVM_CONTROL_BUS_ADDR_AP_CTRL, 0x80); }
この2つの関数を実行しているのと同じ。(先述のInterface1月号の記事を参考にさせていただきました)
app/realtime_webcam内にリアルタイム用のアプリケーションを公開している。USB Webカメラから取得した640pix*480pixの画像から赤信号をリアルタイムに検出する。
開発したHLS IPは検出できる赤信号のサイズが32pix*64pixなので、それより大きなサイズの赤信号を検出したい際は前処理として、SW側で画像を縮小する必要がある。
公開しているアプリケーションでは3種類のサイズの赤信号を検出しようとするので1フレームにつき3回の画像縮小処理・HLS IPの実行が必要になるが、30fps以上の性能を達成できる。
同じリアルタイム用のアプリケーションを全てSWのみで記述し、ホストPCで実行できるようにしたものがcpp/realtimetestに公開している。手元のノートPCで実行しても、1fps未満の性能しか出ない。
手元で実行するとこんな感じで1fps未満ですリアルタイムに検出される様子が見れます。
Ultra96でSWのみとHWアクセラレータありで320pix*240pix画像に対する処理時間を比較評価したところ、
SWのみ :6.22milisec / 160fps
HW使用:1700milisec / 0.58fps
結果、約275倍の高速化に成功した。やったー。
ちなみに、手元のノートPCで実行した場合、 260milisec / 3.84615fpsなので手元のPCよりも40倍以上は速い。
BRAMについて
BRAMについての工夫について説明する。
ウインドウサイズ32pix*64pixに対してHOG特徴量のセルサイズが8pix*8pix,ブロックサイズが2cell*2cellなので、ウインドウ内のブロックの個数は32/8-1 * 64\8-1、すなわち3*7となる。
このうち縦方向の3つのブロックについての積和演算を並列に行う。1つのブロック内には4つのセルが存在するので、全部で12個の積を並列に計算している。
並列に計算するには重みを保存しているBRAMへのアクセスは並列に行える必要がある。BGRHSVについても考えると、全部で3*4+4*4=28個の配列をHLSの入力に設定して、28個のBRAM GeneratorをVivado上で配置する必要があった。
さすがにこれは煩雑になると思い、ブロック内の4つの重みをまとめた32bit*4=128bitをBRAMの1wordにすることにした。128bitの値を32bitずつにスライスして、積算をするようにしている。
accum_fixed multiply_accum_hog(ap_uint<128> weight, ap_fixed_point ul, ap_fixed_point ur, ap_fixed_point bl, ap_fixed_point br){ ap_fixed_point ul_weight = 0; ap_fixed_point ur_weight = 0; ap_fixed_point bl_weight = 0; ap_fixed_point br_weight = 0; ul_weight.range(31, 0) = weight.range(127, 96); ur_weight.range(31, 0) = weight.range(95, 64); bl_weight.range(31, 0) = weight.range(63, 32); br_weight.range(31, 0) = weight.range(31, 0); return (accum_fixed)ul_weight * (accum_fixed)ul + (accum_fixed)ur_weight * (accum_fixed)ur + (accum_fixed)bl_weight * (accum_fixed)bl + (accum_fixed)br_weight * (accum_fixed)br; }
BRAMへの値の入力について
BRAMの値、すなわちSVMの重みはHLSコード内では32bit固定小数点として表されている。SWからBRAMの値をセットする際、通常のC++ではVivadoHLSが使用しているap_fixed型が存在しないためunsigned int型で、32bitの値を表現する。
これを実現するために、32bitの固定小数点を、ビット列をunsigned intのビット列としてみなした値に変換する必要がある。
このために、高位合成をしないただのユーティリティとしてのVivado HLSプロジェクトutil/ap_fixed_convertを作成した。
python3+scikit-learnで学習したパラメータをweights.hで、
ap_fixed<32, 10> unscaled_weight[1140] = { -0.10424178, -0.030799653, 0.052530228..}
のように宣言しておき、(勿論これによりパラメータは与えた定数と同じ値ではなく、固定小数点の精度で表せる値として宣言される)
それを以下のコードでunsigned intとしてみなした値変換している。
unsigned int convFixedToUint(ap_fixed<32, 10> val){
unsigned int res = 0;
string str = val.to_string(2, false);
str = str.substr(2, str.length() - 2);
unsigned int tmp = 1;
for(int i = str.length() - 1; i >= 0; i--){
if(str[i] == '.') continue;
if(str[i] == '1'){
res += tmp;
}
tmp = tmp << 1;
}
return res;
}
感想・その他
- 5月に1ヶ月くらいで実装した。開発が思うようにいかず、自動運転システムへの赤信号検出システムの組み込みはコンテスト本番の1時間前に完了した。チームメイトに迷惑をかけてしまった。
- 再現・検証はできていないがap_fixed固定小数点間のビット精度が大きいものへのキャストが、C-simの結果とCo-simの結果で異なることがあった。(何かの勘違いで自分が悪かっただけなのかもしれない?)
もしこれが本当だとすると、C-simのときの処理系の解釈と、高位合成の際の処理系の解釈が異なることになる??キャストの方法については高位合成マニュアルUG902をそれなりに読んだが、それでもハマった際は全然解決しなかった。
結局ap_fixedのメソッドrange()を使用することでビット列をコピーすることで回避した。
- 当初は入力画像は640pix*480pixだったが、回路面積が大きいからか?、HLS IP内でタイミングエラーが起きてしまったのでとりあえず画像サイズを320*240サイズに縮小してみた。ちゃんとした最適化は考えきれていません。
- 実はSVMによる誤検知(全く赤信号でないものが赤信号と認識される)が多く、困っている。これは学習データに起因するものではなく、単に線形SVMの限界なのかもしれないと思っている。
- 以前のコンテストの際の実装ではウインドウの数だけHLS IPを呼び出す必要があったが、今回は1フレームにつき数回(検出したいウインドウのサイズの種類の個数回)呼び出すだけで済むので、まずまず目標は達成された。
- 焦ってぐちゃぐちゃに開発していたので、リポジトリを整理・公開するのにかなり時間がかかってしまった。
- いつもTwitter等で助言を下さる方々:本当にありがとうございます・・・!