Windows環境でOpenCV freetype2を使用する
環境
- Windows10
- Visual Studio 2017
- OpenCV 3.4.13
何か
WindowsでOpenCVを使うには、ビルド済みライブラリをダウンロードしてプロジェクトの設定を適切に行えば良い。
qiita.com
freetype2を使って日本語を画像に表示させたいが、ビルド済みのものにはfreetype2は含まれていない。(#include でno such file)
というわけで自前でビルドする。参考リンクの情報の寄せ集め。
Visual Studio 英語パックインストール
vcpkgに必要らしい。
kagasu.hatenablog.com
vcpkg インストール
Microsoftが作っているC++向けパッケージマネージャらしい。存在を知らなかった。
cmdかgit bashで行う
git clone https://github.com/microsoft/vcpkg cd vcpkg git checkout refs/tags/2020.11 #masterではharfbuzzのビルドに失敗した bootstrap-vcpkg.bat vcpkg install freetype vcpkg install harfbuzz
うまくいけばvcpkg\installed以下にlibやdllができているはず。
OpenCVソースダウンロード
https://github.com/opencv/opencv/releases/tag/3.4.13
https://github.com/opencv/opencv_contrib/releases/tag/3.4.13
今回は3.4.13をダウンロード。 contrlibもダウンロードすること。
opencv_contrib/modules/freetype/CMakeLists.txtを下記リンクの通りに書き変える。
How to use OpenCV FreeType module with Visual Studio · GitHub
CMake実行
今回はPythonで使用せずC++だけで使用するのでPythonサポートは全部切った(はず)
参考リンクではanacondaを使用しているようです:
GitHub - BabaGodPikin/Build-OpenCv-for-Python-with-Extra-Modules-Windows-10: This is a step by step guide to build OpenCV with Extra Modules for Python (Anaconda) for Windows without errors. Paticularly, I will use the freetype module in OpenCV-Contrib.
cd <your-opencv-workspace-path>
mkdir build
cd ..
cmake -G "Visual Studio 15 2017"
-B <your-opencv-workspace-path>\opencv-3.4.13\build
-D BUILD_NEW_PYTHON_SUPPORT=OFF
-D BUILD_PYTHON_SUPPORT=OFF
-D BUILD_opencv_python3=no
-D OPENCV_SKIP_PYTHON_LOADER=ON
-D OPENCV_EXTRA_MODULES_PATH=<your-opencv-workspace-path>\opencv_contrib-3.4.13\modules
-D OPEN_CV_FORCE_PYTHON_LIBS=yes
-DCMAKE_TOOLCHAIN_FILE=<your-vcpkg-path>\scripts\buildsystems\vcpkg.cmakeうまくいけばcmakeのログで
-- freetype2: YES -- harfbuzz: YES
みたいなのが表示されているはず。
OpenCVビルド
OpenCV.slnが生成されている。ダブルクリックで起動。
ソリューションエクスプローラーの「CMakeLists->INSTALL」を右クリックしてビルド。VisualStudio上画面中央のDebugとReleaseを切り替えて2回ビルド。
Pythonのオプションを切ったからか、ノートPCでも15分もかからずビルドが終了した。
これらをqiita.comのように設定すれば、freetype2が使える。いい感じのところに配置してPATH環境変数に追加しておく。
utf8の罠
こちらのソースコードを使ってテストさせていただいたが、はじめ「あいうえお」が文字化けされて頭を抱えた。

How to use OpenCV FreeType module with Visual Studio · GitHub
結果として、コンパイル時点で日本語が文字化けしているらしいので、/utf8オプションをつければよい。
/8 (ソースと実行可能文字セットを-8 に設定する UTF ) | Microsoft Docs
無事日本語をMatに描画できるようになりましたとさ。

‘
Ubuntu16.04/18.04 で nvidia-driverを使用すると画面がちらつく問題
PCを組んだ
新しくPCを組み直した。
| M/B | ASRock Steel Legend B550 |
| CPU | Ryzen 7 3700X |
| RAM | CORSAIR DDR4-3200MHz 16GB*4 |
| GPU | ZOTAC GAMING GeForce RTX 2070 SUPER MINI |
| ケース | NZXT H510 Elite |
| クーラー | NZXT KRAKEN X53 |
— lp6m (@lp6m1) 2020年8月5日
電源やSSDなどはこれまでに使用していたものを流用した。
Ubuntu16.04/18.04のインストール
BIOS確認後、インストールメディアを作ってインストールを行うと、
- Ubuntu16.04:nvidia-driverをインストールあと、画面がちらつく
- Ubuntu18.04:インストール画面で既に画面がちらつく
という問題が発生した。
ちらつく、というのは画面に緑色の横線が入ったり、画面全体が点滅する。
BIOS画面やWindowsではそのような症状が起きないので、nvidia-driver側の問題だと思う。
調べてみると、以下のフォーラムにたどり着いた。
www.nvidia.com
この人はUbuntuではなくWindowsらしいけど、ケーブルの問題では?という内容が書かれていた。
購入したグラフィックカードには、HDMI*1, DisplayPort *3 の出力が存在する。DisplayPort-to-DisplayPortのケーブルを持っていなかったので、HDMIで繋いでいた。
DisplayPort-to-HDMIの変換コネクタを介してモニタにHDMI接続してもやはり同様の症状であった。
解決
結局、DisplayPort-to-DisplayPortのケーブルを購入した。DisplayPortで接続すると症状は消えた。
メモ
以下のメモを参考にUbuntu18.04をインストールした。
USBメモリからUbuntu 17.04をインストール時に "cdから追加パッケージをインストールするためのapt設定の試行に失敗しました" と出て終了する - Qiita
Ubuntu 16 / 18 に GTX 1080Ti / RTX2080 の ドライバとCUDAのインストール - Qiita(ログインループの対処)
DNNDK + Ultra96でYOLOv3物体認識onFPGA (その1・FPGA向けデプロイまで)
- はじめに
- 実行環境
- DNNDKのダウンロード・インストール
- Tutorialのダウンロード・とりあえず実行
- darknet(YOLO)で自前のデータを学習
- 自前で学習した重みとネットワークをFPGA向けにデプロイ
はじめに
Deephiという中国の会社がXilinxに買収?されてXilinxからDNNDKとよばれるFPGAにDNNを簡単に実装するフレームワークがリリースされています。

今回はコレをやってみます。機械学習に関する詳しいことを全く理解していなくても適当にコマンドを叩くだけで物体認識onFPGAができてしまいそうです。
https://github.com/Xilinx/Edge-AI-Platform-Tutorials/tree/master/docs/Darknet-Caffe-Conversiongithub.com
実行環境
- Ubuntu16.04 LTS
- GeForce GTX980
- OpenCV 3.3.0
- CUDA 9.0
- CUDNN 7.0.5
UbuntuとCUDAとCUDNNのバージョンはDNNDKフレームワークがサポートするものが限られているので注意。
nvidiaのドライバのせいでログインループに陥ったりして環境構築をするのが大変だった。
自分の環境ではnvidiaドライバはnvidia-418がインストールされていて安定している。(nvidia-430やnvidia-387でログインループに陥った)
DNNDKのダウンロード・インストール
- xlnx_dnndk_v2.08_190201.tar.gz https://www.xilinx.com/member/forms/download/dnndk-eula-xef.html?filename=xlnx_dnndk_v2.08_190201.tar.gz
$tar -xvf xlnx_dnndk_v2.08_190201.tar.gz $cd xilinx_dnndk_v2.08/host_x86 $sudo ./install.sh Ultra96 Inspect system enviroment... [system version] No LSB modules are available. Description: Ubuntu 16.04.6 LTS 16.04 [CUDA version] 9.0.176 [CUDNN version] 7.0.5 Begin to install DeePhi DNNDK tools on host ... Complete installation successfully.
これでDNNモデルを量子化するdecentコマンドや量子化済みモデルをコンパイルするdnnc-dpu1.3.0コマンドが使用できるようになる。
このタイミングで対象ボードを指定するので、Ultra96向けに量子化・コンパイルが行われるのだろう。
Tutorialのダウンロード・とりあえず実行
一旦、チュートリアル通りに実行してみます。
$git clone https://github.com/Xilinx/Edge-AI-Platform-Tutorials
チュートリアルのprerequisitesにも書いてあるようにYOLOの学習済みの重みをダウンロードする必要があります。
$cd Edge-AI-Platform-Tutorials/docs/Darknet-Caffe-Conversion/ $wget https://pjreddie.com/media/files/yolov3.weights $mv yolov3.weights ./example_yolov3/0_model_darknet/ $bash -v tutorial.sh
これでいくつかの圧縮ファイルが解凍されて、必要なプログラムがmakeされます。
おそらく初めて実行すると環境が不十分でdarknetやcaffeのmakeがコケるので、適宜必要なものをインストールしてmakeが通るようにします。
何度も試行錯誤するときにmake cleanされるのはめんどくさいのでtutorial.shのmake cleanをコメントアウトして行いました。
UG1327ではcaffeのビルドに以下が必要と書かれています。参考程度に。
その他にdos2unixやprotobufとかもインストールする必要がありました。すべては覚えていません、スミマセン。
apt-get install -y --force-yes build-essential autoconf libtool libopenblasdev libgflags-dev libgoogle-glog-dev libopencv-dev protobuf-compiler libleveldbdev liblmdb-dev libhdf5-dev libsnappy-dev libboost-all-dev libssl-dev
※私の環境では 『.build_release/lib/libcaffe.so: `cvLoadImage' に対する定義されていない参照です』等でcaffeのビルドに失敗します。
これを回避するためcaffe-master/Makefileの421行目を書き換えました。
USE_PKG_CONFIG ?= 1 #0から変更
darknet(YOLO)で自前のデータを学習
今回は、とりあえずこの2つの障害物を認識してもらうことにします。認識精度などは置いといてとりあえず実行したかったので学習画像は各100枚程度にしました。
学習データの用意
こちらの記事を参考にさせていただいて、自前データの学習を行います。
チュートリアルをクローンしてきた時についてきたdarknet_originを使ってもいいのですが、今回はオリジナルのリポジトリからcloneしたほうで学習を行いました。
YOLOオリジナルデータの学習 - Take’s diary
Yolo v3を用いて自前のデータを学習させる + Yolo v3 & opencv のインストール方法付き(Ubuntu 16.04, Opencv 3.3, Conda) - Qiita
1つめの記事にしたがって、yolov3-voc.cfgのclasses, filtersを3箇所書き換えました。(今回はclasses=2, filters=21)
2つめの記事にしたがって画像のアノテーションを行い、train.txt, test.txtを作成し、obj.data, obj.namesファイルを正しく記述します。
学習を実行
記事通りにデータを用意すれば、以下のコマンドで学習が始まります。
./darknet detector train cfg/obj.data cfg/yolov3-voc.cfg darknet53.conv.74
GPUのメモリが足りずに以下のようなエラーで落ちることがあります。
CUDA Error: out of memory darknet: ./src/cuda.c:36: check_error: Assertion `0' failed.
これはcfg/yolov3-voc.cfgの頭のsubdivisionsを16に変更することで回避しました。参考:darknetでYoLoV3マルチクラス学習 - ロボット、電子工作、IoT、AIなどの開発記録
2時間くらい放置して2000回程度回しました。
2101: 0.069695, 0.069695 avg, 0.001000 rate, 3.346575 seconds, 33616 images
avgの前の値が小さいほどいい感じに学習ができているということだそうです。今回は早く試したいのでとりあえずこの辺で学習は終了。
(重みは100回ごと?に保存されるようです)
学習済みモデルの確認
参考の記事通りに設定を書いていればbackupディレクトリ内に学習済みの重みが保存されているので、これを使って学習がうまくいったか確認します。
./darknet detector test cfg/obj.data cfg/yolov3-voc.cfg backup/yolov3-voc.backup test.jpg -thresh 0.1
これで先ほどの画像が結果として得られました。とりあえずはうまく行ってるようです。簡単にできてしまって凄い。
自前で学習した重みとネットワークをFPGA向けにデプロイ
基本的にはtutorial.shそのままでいいのですが、何故か自動化されて欲しいところが自動化されていなかったので簡単な追記を行いました。
修正したものはここで公開しています。
github.com
tutorial.shのワークフローを簡単に図にしたものを以下に示します。
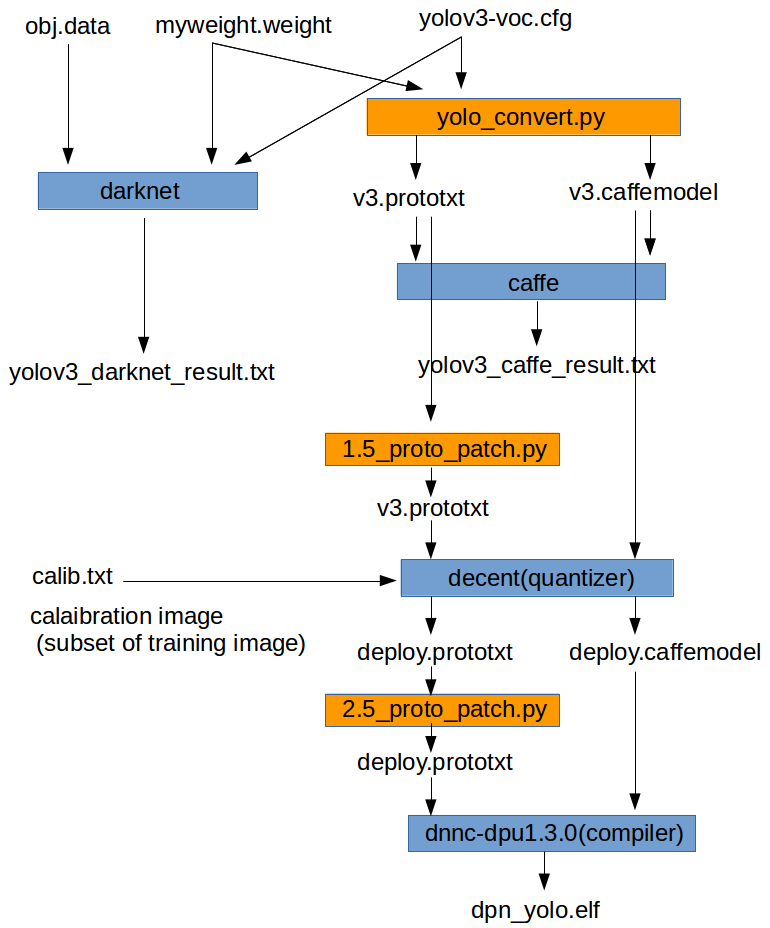
オレンジ色の1.5_proto_patch.pyと2.5_proto_patch.pyは今回私が作成した簡単なコードです。
両方とも、その前のプロセスで出力されたDNNのモデル情報のテキストファイルを次のプロセスに渡すために、一部コメントアウトしたり情報を追加するものになっています。
ドキュメントでは自分で手作業で編集するようになっており、元々のtutorial.shでは、編集済みのファイルをコピーするようになっています。。
これだとモデル情報を変更した際に自動化できないので、雑なコードを記述しました。
自前で学習した重み・ネットワークをデプロイするために修正した箇所は以下の通りです。
0_convert.sh
学習に使用したモデルのcfgファイルと、学習済みの重みを手作業でコピーしておきます。
これらを読み込むように2つの引数を書き換えます。
python ../yolo_convert.py 0_model_darknet/yolov3-voc.cfg 0_model_darknet/myweight.weights 1_model_caffe/v3.prototxt 1_model_caffe/v3.caffemodel
0_test_darknet.sh
同様に自分のモデルと重み、検出クラスのファイルを使って検証を行うように書き換えます。
../darknet_origin/darknet detector valid 5_file_for_test/obj.data 0_model_darknet/yolov3-voc.cfg 0_model_darknet/myweight.weights -out yolov3_results_ cat results/yolov3_results_* >> 5_file_for_test/yolov3_darknet_result.txt cat results/yolov3_results_* >> 5_file_for_test/yolov3_darknet_result.txt
学習時に使用したobj.namesを5_file_for_testディレクトリ内にコピーしておくことも忘れずに。
obj.data
obj.dataは学習時に使用したものから書き換えました。検証を行う対象の画像を1つにするためです。
classes = 2 valid = example_yolov3/5_file_for_test/image.txt names = example_yolov3/5_file_for_test/obj.names
ここで検証対象の画像ファイルのパスが書かれているテキストファイルがimage.txtであると指定されています。
image.txtの中身はtest.jpgなので書き換える必要なし。test.jpgを自分が検証に使用したい画像に差し替えます。
1_test_caffe.sh
クラス数を自分が学習したクラス数に書き換えます。(今回は2)
これをしないと出力されるdetection.jpgに枠が無数に表示されておかしなことになった。
./../caffe-master/build/examples/yolo/yolov3_detect.bin 1_model_caffe/v3.prototxt \ 1_model_caffe/v3.caffemodel \ 5_file_for_test/image.txt \ -out_file 5_file_for_test/yolov3_caffe_result.txt \ -confidence_threshold 0.005 \ -classes 2 \ -anchorCnt 3
5_file_for_test/calib.txt
何をやっているのかは正直よくわかっていませんが、2_quantize.shで量子化を行う際にキャリブレーションという作業が行われるようです。
チュートリアルには
The 5_file_for_test/calib_data folder contains some images from the COCO dataset, to be used for the calibration process.
とかいてあるので、学習データのサブセットのファイル名を記述しておけばよいようです。
フォーマットはファイル名 1で、1には特に意味がないらしいです。
学習時に作成したtrain.txtのデータを整形してcalib.txtとしてあげればOKです。
指定したパスに学習画像もコピーしてあげる。
1.5_proto_patch.py, 2.5_proto_patch.py
0_convert.sh, 2_quantize.shで生成されたモデル情報は次プロセスまでに手作業で書き換える必要があります。
先述の通りなぜか元々は編集済みのものをコピーして書き換えるようになっていましたが、汎用性がないので適当にコードを書きました。
コードはここにあります。Edge-AI-Platform-Tutorials/docs/Darknet-Caffe-Conversion/example_yolov3 at master · lp6m/Edge-AI-Platform-Tutorials · GitHub
tutorial.sh
caffe-masterをビルドした後にcd ..抜けのミスがあるのでそれを追記。
1.5_proto_patch.pyと2.5_proto_patch.pyを途中で呼び出すように修正。
ここには#check the environment以降をそのまま貼り付けておきます。
#check the environment python -c "import caffe; print caffe.__file__" cd .. ############################################################################ # Section 3.0 ############################################################################ cd example_yolov3/ rm results/* rm 5_file_for_test/yolov3_*_result.txt # step 0: Darknet to Caffe conversion bash -v 0_convert.sh # step 1: test Darknet and Caffe YOLOv3 models bash -v 0_test_darknet.sh bash -v 1_test_caffe.sh # step 2: quantize YOLOv3 Caffe model cp 1_model_caffe/v3.caffemodel ./2_model_for_quantize/ cp 1_model_caffe/v3.prototxt 2_model_for_quantize/v3.prototxt python 1.5_proto_patch.py 2_model_for_quantize/v3.prototxt 416 416 5_file_for_test/calib.txt 5_file_for_test/calib/ bash -v 2_quantize.sh # step 3: compile ELF file # cp 3_model_after_quantize/ref_deploy.prototxt 3_model_after_quantize/deploy.prototxt python 2.5_proto_patch.py 3_model_after_quantize/deploy.prototxt bash -v 3_compile.sh # step 4: prepare the package for the ZCU102 board cd .. cp example_yolov3/4_model_elf/dpu_yolo.elf yolov3_deploy/model/ tar -cvf yolov3_deploy.tar ./yolov3_deploy gzip -v yolov3_deploy.tar
実行
ここまで修正すれば、自前のデータを読み込むようになったので、tutorial.shを実行してデプロイ!です。
感覚的には2の量子化は一瞬で、3のコンパイルが結構時間かかるっぽいです。
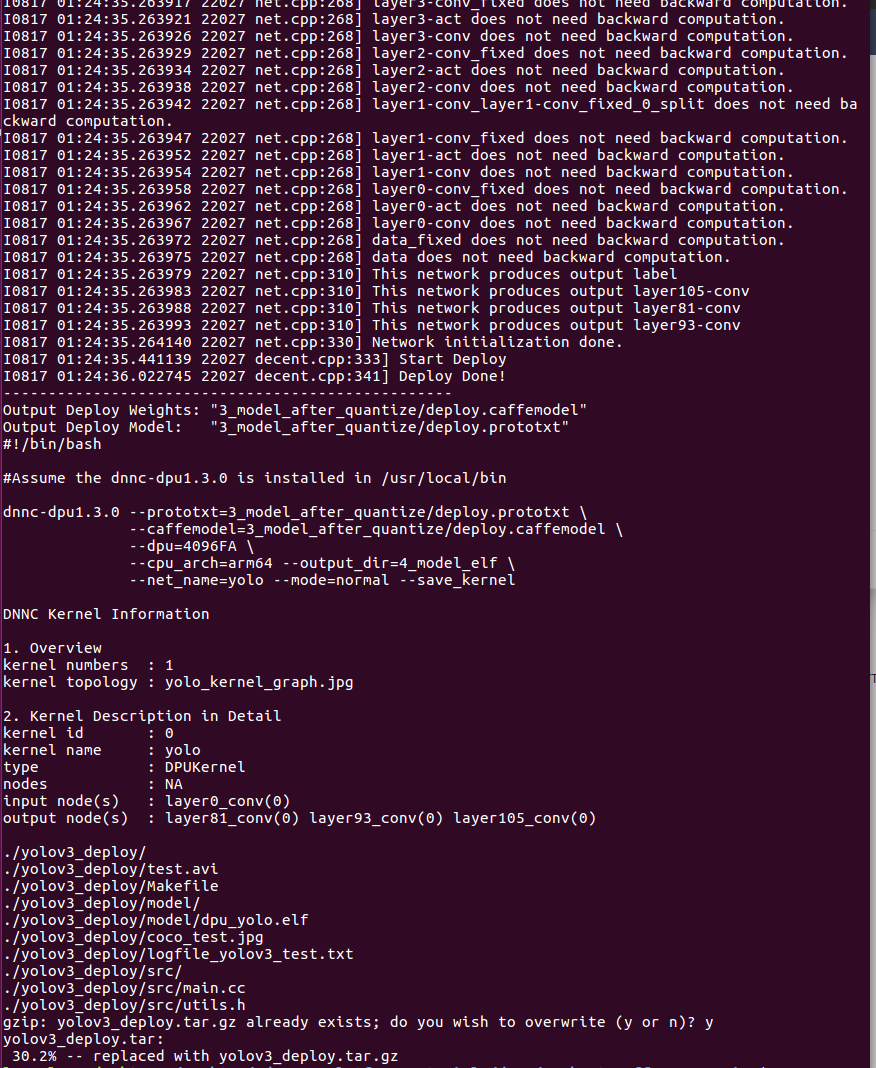
エラーが特にでていなければ終了。最後にデプロイしたデータをtar.gzに圧縮されるか聞かれます。
生成されたyolov3_deploy/model/dpu_yolo.elfが生成されたネットワークのようです。
yolov3_deploy内のテストデータ(coco_test.jpg, test.avi)は元々のデータなので手作業で差し替えました。
わりと1日ですんなりできてしまった。次回は実機で動作確認しようと思います。
ZC102じゃなくてUltra96だけどうまくいくかな?
Vivado HLSでRGB/HSV + HOG + SVMの高速物体検出をする2(完成)
前回(Vivado HLSでHOG+SVMの高速物体検出をする1(2つめのコンポーネントまで作成) - lp6m’s blog)の続き。
(相変わらず時間がすごくたってしまったけど)
何をつくったのか
ココにHLSプロジェクト・Vivadoプロジェクト・DeviceTreeなど全ておいています。とりあえずの使い方などはREADMEに書きました。
Python3+scikit-learnでLinear SVMの学習を行う。学習したパラメータを取り出して、C++に推論のコードを移植。その後推論コードをFPGA向けのアルゴリズムを使ってHLS IPを作成。
SWのみで実行した場合よりも270倍以上高速化された!!
github.com
このプロジェクトはHEART 2019 Design Contestのために開発しました。
コンテストで赤信号を検出して停止する様子:
www.youtube.com
仕様
作成したHLS IPの最終的な仕様は以下のようになった。
- スライディングウインドウ法 * SVMで物体検出
- 入力:320pix*240pix BGR画像(1画素32bit, 8bit不使用)((OpenCVではデフォルトがRGBではなくBGRの順。24bitでなく32bitにしているのは転送に使用するDMAが2のべき乗のデータ幅しか使えないため)
- ウインドウサイズ:32pix*64pix
- 出力:891個のウインドウ領域に対するSVMの出力
- 特徴量:HOG(Histogram of Oriented Gradients)・BGR,HSV画素値
基本的なアルゴリズムは参照している論文の通り。これにBGR/HSV特徴量を追加した。
HOGについてはセルサイズ8pix, ブロックサイズ2*2,ヒストグラムのビン数9で論文と同様。
BGR/HSV画素特徴量に関しては以前のRFのとき(FPGAデザインコンテスト@FPT2018 開発記 - lp6m’s blog)同様、32pix*64pix画像を8*8に圧縮したものを使用する。
参照した論文との仕様の違い
HLS IP全体像
作成したHLS IPには以下の図のような構成になっており、トップファンクションから呼ばれる関数が6つある(最後のmergeはトップファンクション内に書いている)。
画像の左部分がHOG, 右部分がBGRHSVの特徴量に対する処理となっている。左部分の4つの関数は論文を参考に実装したもの。
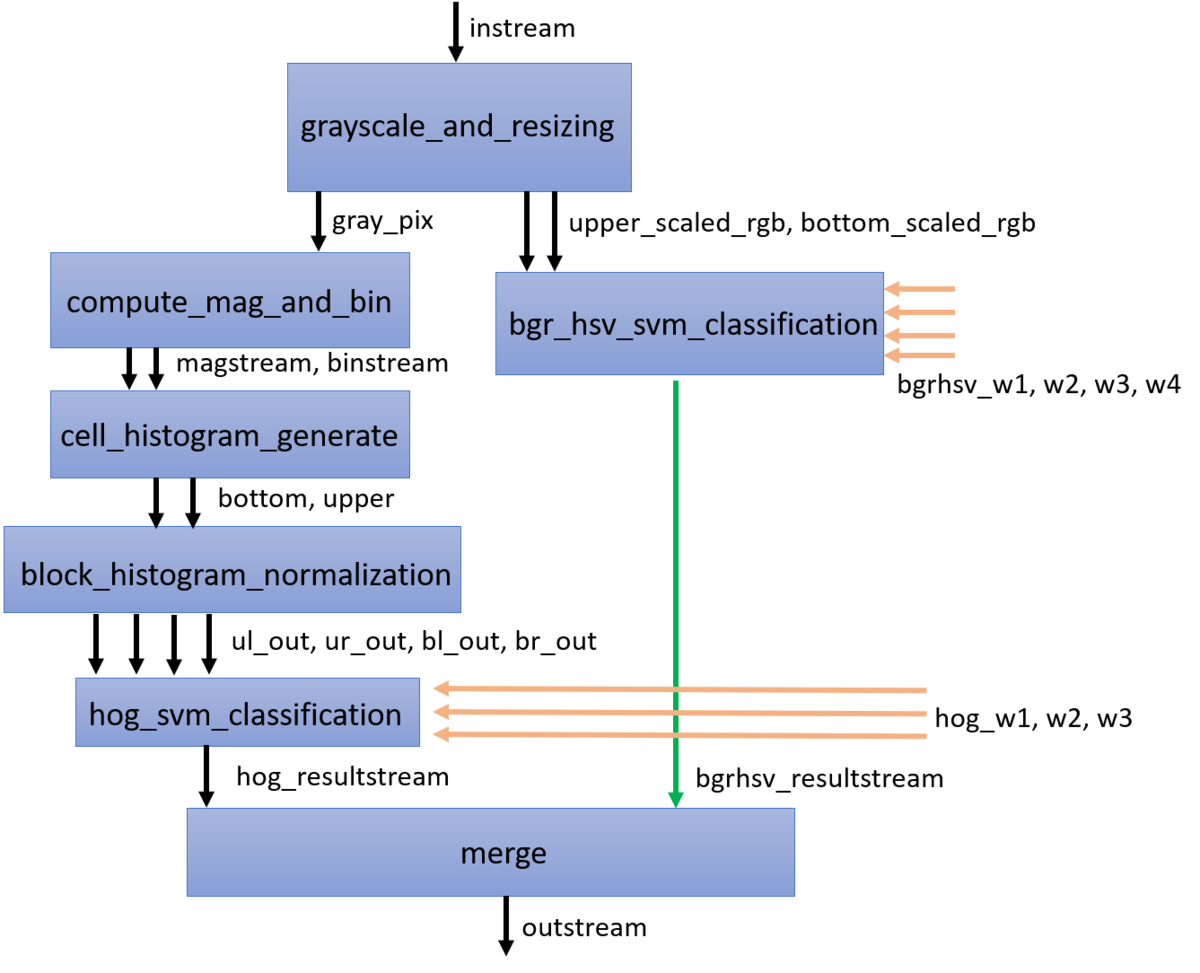
オレンジ色の矢印は外部BRAMからのSVMの重みを表す。
関数間のFIFOは#pragma HLS DATAFLOWを使えばVivado HLSが適切にFIFOを設定してくれるが、関数のバイパスには対応しておらず、緑の矢印部分にはFIFOが挿入されない。
左部分のHOG部分と右部分のBGRHSV部分では、値がでてくるまでのレイテンシが異なるので、FIFOを挿入する必要がある。
このため、#pragma HLS STREAM variable = bgr_hsv_resultstream depth = 100 dim = 1で明示的にFIFOを挿入している。
前回の記事時点ではcompute_mag_and_binとcell_histogram_generateを作成しただけだった。
HOG部分は基本的には論文そのまま実装しているので省略。何故か論文の図にはFIFOとかBRAMとだけ書いててどのようなアクセスをするのかが書いていなかったりして理解するのに少し時間がかかった。
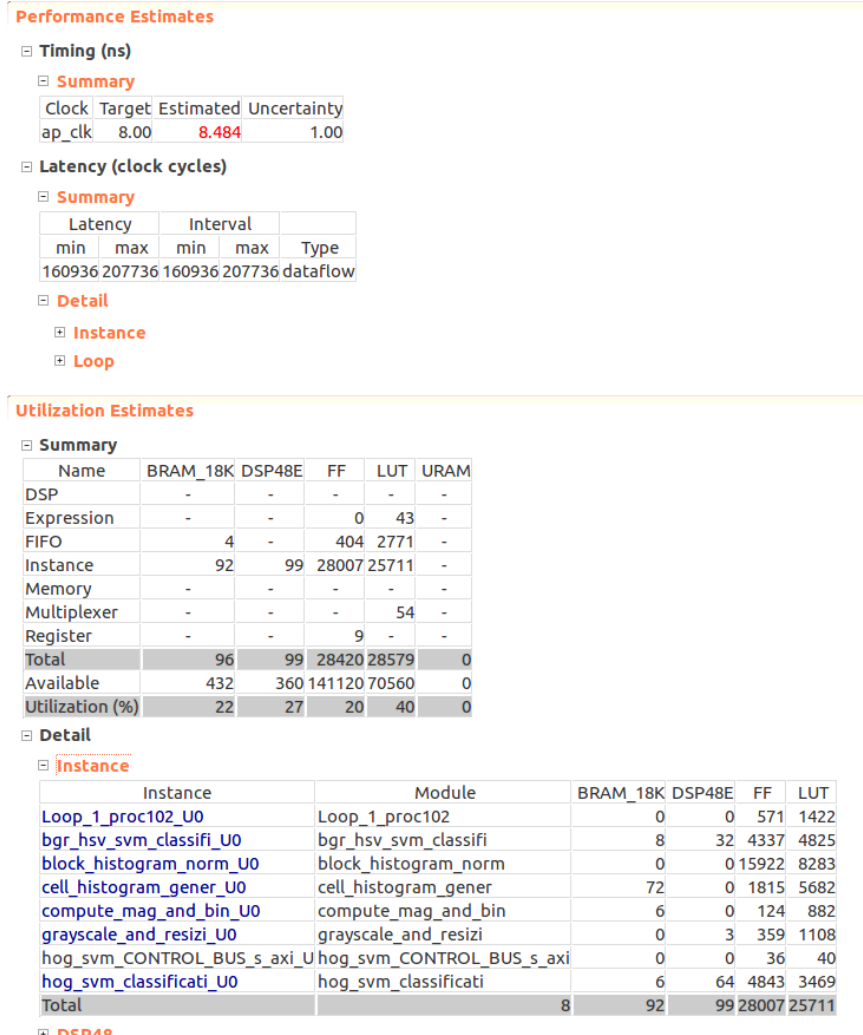
HLS高位合成結果
合成結果は以下の通り。レイテンシがmin:160936, max:207736となっている。1画素に対して207736/320/240=2.7クロック程度かかる計算になる。ループのパイプライン化が完全にできていないところが何箇所かあるが、回路面積との兼ね合いでこのような結果になった。
回路面積を減らすために積算・除算のところに#pragma HLS allocation instances= limit=2を挿入している。
制約は8nsで合成結果は8.48snsになっているが、100MHzのクロックしか刺さないので問題ないとした。
Vivadoブロックデザイン

作成したHLS IPをDMA経由でZynq PSと接続する。
HLS IPのBRAMからの重み入力にはBlock Memory Generatorと接続する。Block Memory GeneratorとAXI BRAM Controllerを接続し、AXI BRAM ControllerをAXI Interconnect経由で接続することでBRAMの値をPSから読み書きできる。 参考:VIVADO HLS Training - BRAM interface #06 - YouTube
DMAをカスタマイズする部分としては以下の通り。
- シンプルモードしか使用しないのでEnable Scatter Gather Engineをオフ
- Width of Buffer Length Registerを21にする(データ転送量が320*240*32+891*32bit < 2^21のため)参考:FPGA+SoC+LinuxでXilinx AXI DMAを試す — ふがふが
HLS IPの動作周波数は100MHzとした。
回路を合成した結果、タイミングエラーはなかった。
Ultra96へのOSインストール・Device Tree Overlay
Ultra96での実機動作のためのアレコレには、こちらのリンクを大変参考にさせていただきました。ありがとうございます。
qiita.com
proc-cpuinfo.fixstars.com
また、udmabufを使用したDMA制御のサンプルに、Interface1月号の「最強FPGAボードで人工知能カリカリ画像認識」を大変参考にさせていただきました。ありがとうございます。
shop.cqpub.co.jp
LinuxからFPGA上のIPコアを制御するための簡単な説明を書くと(嘘を書いていたら指摘して下さい)、FPGA IPの制御のためのレジスタはメモリマップされており、指定のアドレス(アドレスはAddress Editorで見れる)を制御することでFPGA IPを制御することができる。
一番単純なのはdevmemコマンドで物理アドレスを指定して直接レジスタを制御する方法で、C言語だとmmapして仮想アドレスを取得し、そのアドレスに値を書き込むことで実現できる。ただ物理アドレスを直接指定して制御するのは、OS等が使用しているメモリを破壊する可能性があり危険なので、デバイスドライバを記述するのがよいとされる。(udmabufはコレ!)xilinxのvideo系のデバイスドライバはこの辺にあったりする(ドキュメントとか例が全然ない!)。
ただ自作のIP(今回はHLS IP)ごとにデバイスドライバを作成するのも面倒なので実験段階ではUIOという仕組みを使用することが多い。デバイスツリー*1にgeneric-uioと記述し、使用するアドレスの範囲を記述する。これで比較的簡単・安全にIPを制御することができる。デバイスツリーによりLinux OSにはUIOデバイスとして/dev/uio に登録される。プログラムからは/dev/uioをopenしてからmmapして仮想アドレスを取得する。
これまではLinuxカーネルイメージの作成にPetaLinuxを使用していた。カーネルイメージを作成する際にデバイスツリーを使用していたので、回路を変更する度にカーネルイメージをビルドする必要があった。
今回からは最近流行り(?)のLinuxカーネルのDevice Tree Overlayという機能を使用することで、実機からFPGAのコンフィグレーション・デバイスツリーのオーバレイができるようになった!参考:FPGA+SoC+LinuxでDevice Tree Overlayを試してみた - Qiita
注意点としては、udmabufのためのDeviceTreeファイル(udmabuf0.dts, udmabuf1.dts)に記載するバッファサイズを余裕をもって大きく設定した際、合計が2^21(Vivadoで設定したDMAのWidth of Buffer Length Registerの値)を超えないようにすること。
当たり前ですが、ハマってしまったので。
IFレイヤー・アプリケーションの作成・性能評価
まずgithubに公開したapp/hog_svm_testについて説明する。
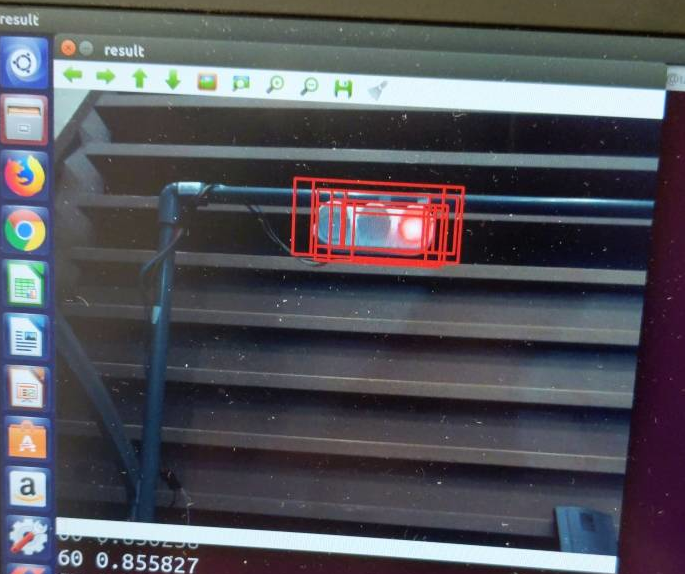
このアプリケーションは320pix*240pixのframe.pngから赤信号を検出し、検出結果をresult.pngに保存する。
result.pngはこんな感じになる。赤信号が正しく検出されていることが確認できる。

SVMの重みはweights.jsonに保存されている。これを読み込んで、BRAMに書き込む。その後DMAで入力画像を転送・結果を転送している。
app/hog_svm_test/main.cppの51,52行目の
regs_write32(hls_regs, 0x01); //start regs_write32(hls_regs, 0x80); //enable autorestart
はVivado HLSで合成時に自動生成されるドライバファイル、hls/hog_svm/solution1/impl/ip/drivers/hog_svm_v1_0/src/xhog.svm.c内の
void XHog_svm_Start(XHog_svm *InstancePtr) { u32 Data; Xil_AssertVoid(InstancePtr != NULL); Xil_AssertVoid(InstancePtr->IsReady == XIL_COMPONENT_IS_READY); Data = XHog_svm_ReadReg(InstancePtr->Control_bus_BaseAddress, XHOG_SVM_CONTROL_BUS_ADDR_AP_CTRL) & 0x80; XHog_svm_WriteReg(InstancePtr->Control_bus_BaseAddress, XHOG_SVM_CONTROL_BUS_ADDR_AP_CTRL, Data | 0x01); } void XHog_svm_EnableAutoRestart(XHog_svm *InstancePtr) { Xil_AssertVoid(InstancePtr != NULL); Xil_AssertVoid(InstancePtr->IsReady == XIL_COMPONENT_IS_READY); XHog_svm_WriteReg(InstancePtr->Control_bus_BaseAddress, XHOG_SVM_CONTROL_BUS_ADDR_AP_CTRL, 0x80); }
この2つの関数を実行しているのと同じ。(先述のInterface1月号の記事を参考にさせていただきました)
app/realtime_webcam内にリアルタイム用のアプリケーションを公開している。USB Webカメラから取得した640pix*480pixの画像から赤信号をリアルタイムに検出する。
開発したHLS IPは検出できる赤信号のサイズが32pix*64pixなので、それより大きなサイズの赤信号を検出したい際は前処理として、SW側で画像を縮小する必要がある。
公開しているアプリケーションでは3種類のサイズの赤信号を検出しようとするので1フレームにつき3回の画像縮小処理・HLS IPの実行が必要になるが、30fps以上の性能を達成できる。
同じリアルタイム用のアプリケーションを全てSWのみで記述し、ホストPCで実行できるようにしたものがcpp/realtimetestに公開している。手元のノートPCで実行しても、1fps未満の性能しか出ない。
手元で実行するとこんな感じで1fps未満ですリアルタイムに検出される様子が見れます。
Ultra96でSWのみとHWアクセラレータありで320pix*240pix画像に対する処理時間を比較評価したところ、
SWのみ :6.22milisec / 160fps
HW使用:1700milisec / 0.58fps
結果、約275倍の高速化に成功した。やったー。
ちなみに、手元のノートPCで実行した場合、 260milisec / 3.84615fpsなので手元のPCよりも40倍以上は速い。
BRAMについて
BRAMについての工夫について説明する。
ウインドウサイズ32pix*64pixに対してHOG特徴量のセルサイズが8pix*8pix,ブロックサイズが2cell*2cellなので、ウインドウ内のブロックの個数は32/8-1 * 64\8-1、すなわち3*7となる。
このうち縦方向の3つのブロックについての積和演算を並列に行う。1つのブロック内には4つのセルが存在するので、全部で12個の積を並列に計算している。
並列に計算するには重みを保存しているBRAMへのアクセスは並列に行える必要がある。BGRHSVについても考えると、全部で3*4+4*4=28個の配列をHLSの入力に設定して、28個のBRAM GeneratorをVivado上で配置する必要があった。
さすがにこれは煩雑になると思い、ブロック内の4つの重みをまとめた32bit*4=128bitをBRAMの1wordにすることにした。128bitの値を32bitずつにスライスして、積算をするようにしている。
accum_fixed multiply_accum_hog(ap_uint<128> weight, ap_fixed_point ul, ap_fixed_point ur, ap_fixed_point bl, ap_fixed_point br){ ap_fixed_point ul_weight = 0; ap_fixed_point ur_weight = 0; ap_fixed_point bl_weight = 0; ap_fixed_point br_weight = 0; ul_weight.range(31, 0) = weight.range(127, 96); ur_weight.range(31, 0) = weight.range(95, 64); bl_weight.range(31, 0) = weight.range(63, 32); br_weight.range(31, 0) = weight.range(31, 0); return (accum_fixed)ul_weight * (accum_fixed)ul + (accum_fixed)ur_weight * (accum_fixed)ur + (accum_fixed)bl_weight * (accum_fixed)bl + (accum_fixed)br_weight * (accum_fixed)br; }
BRAMへの値の入力について
BRAMの値、すなわちSVMの重みはHLSコード内では32bit固定小数点として表されている。SWからBRAMの値をセットする際、通常のC++ではVivadoHLSが使用しているap_fixed型が存在しないためunsigned int型で、32bitの値を表現する。
これを実現するために、32bitの固定小数点を、ビット列をunsigned intのビット列としてみなした値に変換する必要がある。
このために、高位合成をしないただのユーティリティとしてのVivado HLSプロジェクトutil/ap_fixed_convertを作成した。
python3+scikit-learnで学習したパラメータをweights.hで、
ap_fixed<32, 10> unscaled_weight[1140] = { -0.10424178, -0.030799653, 0.052530228..}
のように宣言しておき、(勿論これによりパラメータは与えた定数と同じ値ではなく、固定小数点の精度で表せる値として宣言される)
それを以下のコードでunsigned intとしてみなした値変換している。
unsigned int convFixedToUint(ap_fixed<32, 10> val){
unsigned int res = 0;
string str = val.to_string(2, false);
str = str.substr(2, str.length() - 2);
unsigned int tmp = 1;
for(int i = str.length() - 1; i >= 0; i--){
if(str[i] == '.') continue;
if(str[i] == '1'){
res += tmp;
}
tmp = tmp << 1;
}
return res;
}
感想・その他
- 5月に1ヶ月くらいで実装した。開発が思うようにいかず、自動運転システムへの赤信号検出システムの組み込みはコンテスト本番の1時間前に完了した。チームメイトに迷惑をかけてしまった。
- 再現・検証はできていないがap_fixed固定小数点間のビット精度が大きいものへのキャストが、C-simの結果とCo-simの結果で異なることがあった。(何かの勘違いで自分が悪かっただけなのかもしれない?)
もしこれが本当だとすると、C-simのときの処理系の解釈と、高位合成の際の処理系の解釈が異なることになる??キャストの方法については高位合成マニュアルUG902をそれなりに読んだが、それでもハマった際は全然解決しなかった。
結局ap_fixedのメソッドrange()を使用することでビット列をコピーすることで回避した。
- 当初は入力画像は640pix*480pixだったが、回路面積が大きいからか?、HLS IP内でタイミングエラーが起きてしまったのでとりあえず画像サイズを320*240サイズに縮小してみた。ちゃんとした最適化は考えきれていません。
- 実はSVMによる誤検知(全く赤信号でないものが赤信号と認識される)が多く、困っている。これは学習データに起因するものではなく、単に線形SVMの限界なのかもしれないと思っている。
- 以前のコンテストの際の実装ではウインドウの数だけHLS IPを呼び出す必要があったが、今回は1フレームにつき数回(検出したいウインドウのサイズの種類の個数回)呼び出すだけで済むので、まずまず目標は達成された。
- 焦ってぐちゃぐちゃに開発していたので、リポジトリを整理・公開するのにかなり時間がかかってしまった。
- いつもTwitter等で助言を下さる方々:本当にありがとうございます・・・!
Vivado HLSでHOG+SVMの高速物体検出をする1(2つめのコンポーネントまで作成)
あらまし
前回(FPGAデザインコンテスト@FPT2018 開発記 - lp6m’s blog)からかなり時間が経ってしまった。
コンテストの際の信号検出の実装は、
カメラ画像から物体を検出する際にウインドウを動かしていくスライディングウィンドウ法を使用していた。
FPGAに実装したIPは1ウインドウに対する特徴量の抽出しかできないため、1フレームの処理のために何度もHWを呼び出す必要があり、あまり高速化できているとは言えない状態だった。
次のコンテストに向けて、というか趣味的にももう少し性能を向上したい。
色々と「物体検出をFPGAで高速化」みたいなものを探した結果、今回はこの論文にたどり着いた。
ポイントは、
- HOG+SVMによる人間認識
- FPGAのみ(Pure)で、CPUやDRAMを使用しない
- 1フレームの画像をパイプライン的に処理できる
- スライディングウインドウのウインドウの動く間隔は、セルサイズと同じ(8pix)
- 600*800のフレーム画像に対して162fpsで判定が可能
ということ。
論文は全部で16ページあって、結構詳しめに書いてくれている。
とりあえずこの論文を読んで、パクってそのまま実装していくことにする。
多分論文ではHLSは使用しておらず、RTLで書いている気がする。
将来的にはRGB/HSV特徴量も加えた判定ができるようにしたい。
論文の図をココに貼るのは気が引けるので、番号で参照することにする。
HOG+SVMによる高速検出は、大きく4つのコンポーネントからなっており、順に作っていく予定。
- FIgure3: Diagram of the Gradient Calculation sub-module in the proposed structure
- FIgure5: Diagram of the Cell Histogram Generation sub-module in the proposed structure
- Figure6: Diagram of the Block Histogram Normalization sub-module in the proposed structure
- Figure7: Diagram of the SVM Classification in the proposed stucture.
(以後1.〜4.の番号で参照する)
今回やったこと
1.と2.の2つのコンポーネントを作った。
1.はグレースケールのデータからmagnitudeとbin_indexを計算し、出力する
2.は8pix*8pixのセルごとに・ヒストグラムのbin_indexごとにmagnitudeを合算して、出力する。
今回のコミットのリンクを貼る。
github.com
合成のメイン:main.cppは以下。
ImageDetectionHW2/main.cpp at afe31ceca667bf795b03494b05265073333af3f3 · lp6m/ImageDetectionHW2 · GitHub
テストベンチmain_tb.cppは、
1,の処理はHW用の実装を動作させ、次に2.の処理をHW向けとSW向けそれぞれの実装を動作させて、出力の一致を確かめている。
(2.の入力のために両者で1.のHW用の実装を使っている理由は、SW用の実装とHWの実装の結果が違うため。ここ参照)
論文と今回の実装の違い
- 入力画像サイズが論文は600*800, 今回の実装は480*640
- bin_indexの決め方や、gradientの計算方法は論文よりも軽い計算にしている(特に意味はない、前の実装を引き継いでいる)
- ウインドウのサイズが論文では7*15, 今回の実装では未定
問題点1
テストベンチで出力を確認したが、問題なかった。
合成結果は以下の通り。(Detail->Instanceの上が2.で下が1.)

1.はLatencyが307206≒480*640となっており、1cycleで1pixの処理ができている。
2.のInitiation Intervalが1を達成できず、2になってしまっている。
合成中のログは以下の通り。
INFO: [SCHED 204-61] Pipelining loop 'loop_y_loop_winx_loop_cell_index'.
WARNING: [SCHED 204-68] Unable to enforce a carried dependence constraint (II = 1, distance = 1, offset = 1)
between 'store' operation (/home/lp6m/Xilinx/Vivado/2017.4/common/technology/autopilot/hls/hls_video_mem.h:765->hog_svm/src/main.cpp:123) of variable 'tmp.data.V', hog_svm/src/main.cpp:121 on array 'cellbuf[0].val[1]', hog_svm/src/main.cpp:100 and 'load' operation ('tmp.data.V', /home/lp6m/Xilinx/Vivado/2017.4/common/technology/autopilot/hls/hls_video_mem.h:729->hog_svm/src/main.cpp:122) on array 'cellbuf[0].val[1]', hog_svm/src/main.cpp:100.
INFO: [SCHED 204-61] Pipelining result : Target II = 1, Final II = 2, Depth = 6.うーん、どうやら依存があるみたい。
問題点2
2.のコンポーネントでは、
8*480個の入力ごとに、「8個の入力ごとに9個の出力データが完成」になる。
ループ内でデータが完成したときに9個連続で同じポートから出力していると、出力のほうに律速してしまう。
とりあえず今は出力を9個つくって並列に出力できるようにしている。
ちなみに、ap_axisのdataメンバを配列にする、といったことはできなかった。(FPGAの部屋 Vivado HLSでのAXI4-Stream のテンプレートを作成する1参照)
他の解決策としては、
- 9個のデータをビットを並べた1つのデータとして出す
- 何らかのバッファをおいて後から出力する
が考えられる。
とりあえず3.4.を作ってから2.の問題点を考えるようにしよう。
FPGAデザインコンテスト@FPT2018 開発記
FPGAデザインコンテスト@FPT2018 開発記
はじめに
この記事はFPGA Advent Calendar 15日目の記事です。
先日FPT2018にて行われたFPGAデザインコンテストに参加しました。
FPGA搭載の自動運転ロボットが、決められたコースを走りながらいくつかの課題(障害物回避・信号検知・人間検知)をこなすといった内容のものでした。
FPGAボードに搭載されているハードマクロCPUの使用は認められています。外部との通信が完全に禁止されているのですべての判断・計算をロボットに搭載されたシステムで行う必要があり、効率的なシステムを構築する必要があります。
第8回 相磯秀夫杯 FPGAデザインコンテスト
大学院の同じ研究室の友人と2人で参加し、なんとか優勝することができました。
ここではその開発記・自分が担当した実装の内容について記録したいと思います。
友人とは完全に分業制で開発を行ったため、自動運転システムの進捗は全くわかりません。
まずは走行の様子の動画です。障害物の回避・信号の検知に成功しています。途中でコースアウトしてしまったのが残念・・
ZytleBot 本戦
時系列と、信号検出の詳細について紹介します。
だらだら書いてたらだいぶ長くなってしまいました・・ブログってもっと完結に書いたほうがいいのかな、
自分が作ったものはココにおいてます。全く整理していないので整理していきます・・
github.com
時系列
5月・6月
コンテストの存在を知る
7月
- コンテストに参加したいと指導教員に伝えて、ZYBO + TurtleBot3を使用することを決めた
(研究室にTurtleBot3が存在したから選んだだけ)
- ココの記事を参考にZYBOにUbuntu OSを搭載した
( USBの端子が2つある8ポートハブの片方をZYBOに、もう片方をモバイルバッテリーに接続することで無理矢理電源を安定させている)
BSH8U01 USB2.0ハブ 8ポートタイプ : USBハブ | バッファロー
8月
(デバイスドライバのソースコードを読んだり、デバイスツリーについて勉強した)
- 画像が取得できるようになり、自動運転SWの開発を完全にチームメイトに丸投げする
大学の地下室のコース設置なども丸投げしてしまって申し訳なかった
- 某社夏期インターンシップに1ヶ月間参加
9月
- 慶応大学日吉キャンパスにて国内大会が開かれる。
カメラ画像の取得以外は完全にSWで頑張っている状態で3位入賞。自分の貢献はほぼゼロ。
1位で優勝したチームが圧倒的強く、FPGAをうまく活用していることに憧れる、Twitterで交流する
10月
- あと2ヶ月しかないという状況のなかFPTに向けて開発開始
- PCamで取得した画像をFPGAで処理してからCPUに転送しようとしていろいろやってみる。
- 結局1ヶ月かかって失敗(現在も未解決)
10月末〜11月
あと1ヶ月で何ができるかを考えた
方針は、
- むやみやたらに挑戦せず、頑張れば出来そうなラインをみつけて頑張る
- 実装が公開されているものを探しまくってパクる・ひたすらググる
- 必ず1ヶ月で完成させる、妥協するところは妥協する
信号検出ならなんとかなりそうということになり、信号の検出を目指すことに。
とりあえず3Dプリンタを購入してもらったので信号機を作った。
ガバガバ工作だけどFPTデザインコンテストのために信号作った pic.twitter.com/aP7ECKkFRR
— lp6m (@lp6m2) 2018年11月7日
「ゼロから作るディープラーニング」を斜め読みして、「無理」となったので、ディープラーニング以外の機械学習アルゴリズムで、実装を完全に理解してフルスクラッチで実装できるアルゴリズムを探した。
以下の記事を参考にした。ありがとうございます。。
HOG特徴量とSVMを使った自動車の検出 - くーろんログ
https://qiita.com/mikaji/items/3e3f85e93d894b4645f7
ランダムフォレストとSVMの使い分け - 静かなる名辞
ランダムフォレストのつくりかた(C++の実装例つき) - じじいのプログラミング
ZYBOにMIPI経由で接続されているPCamとは別にWebカメラを取り付けて、Webカメラから取得した画像から信号を検出する。
PCamは下向き、Webカメラは上向きに取り付けた。

次に実装が落ちているものを探した。以下のリポジトリにたどり着いた。
①HOG+SVMによる人間検出 on Zedboard
GitHub - nikkatsa7/HOG_Zedboard: A real time Histogram of Oriented Gradients Implementation on FPGA
Real time HOG implementation on Zedboard - Xilinx XOHW18-222 - YouTube
・こちらはXilinxのコンペで優勝したらしい
・LinuxからAXI4/AXI-Lite経由でHLS IPを使う実装が公開されているので採用
・実はこのHOGのHLS実装が間違っていることに後々気づく
②Python scikit-learnでRFによる車の検出
GitHub - t-lanigan/vehicle-detection-and-tracking: Detecting vehicles in a video stream using machine learning. Adds on to lane detection project.
・scikit-learnなんて使ったことないけどとりあえず実装が落ちていたので採用
この2つを参考に信号検出器を作成した。どうにか1ヶ月で完成させないといけなかったのでスケジュール管理したりしていた。

HOG特徴量とRFを使った信号検出器の作成
結局やったことは①と②の実装を組み合わせただけなんですが、、、まあ何をやったか書いていきます。
ランダムフォレスト・物体認識の仕組みの理解
まずは、②のソースコードやRFに関する記事を読んで、何をやっているのかを理解した。
(たぶん当たり前すぎて今更な内容なのでしょうが、恥ずかしながらそれすら知りませんでした。学部でこんな勉強したっけ・・?自分にとっては初めてだったので、まとめておきます。)
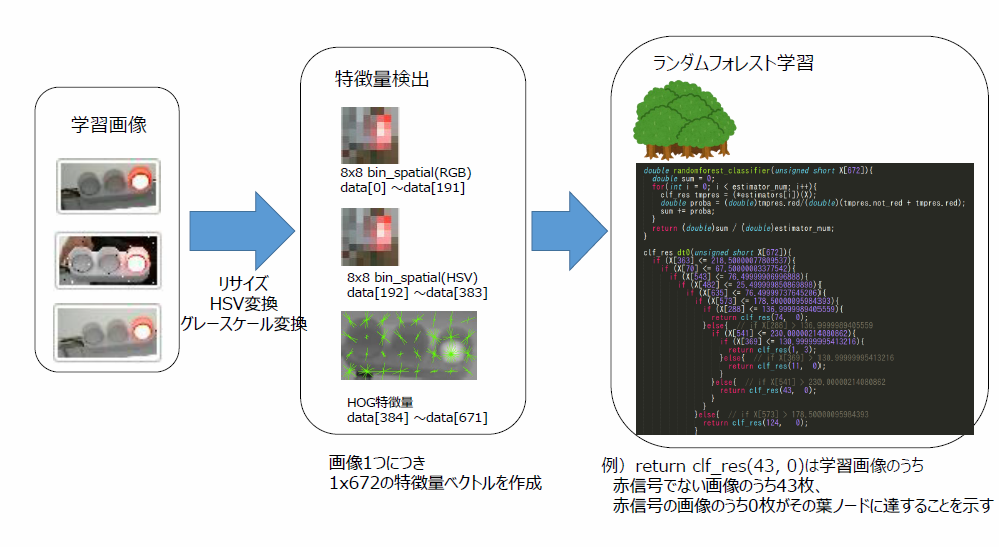
・学習
信号の画像(32x64)→特徴量の抽出(画素・ヒストグラム・HOG) → RFの決定木を作成
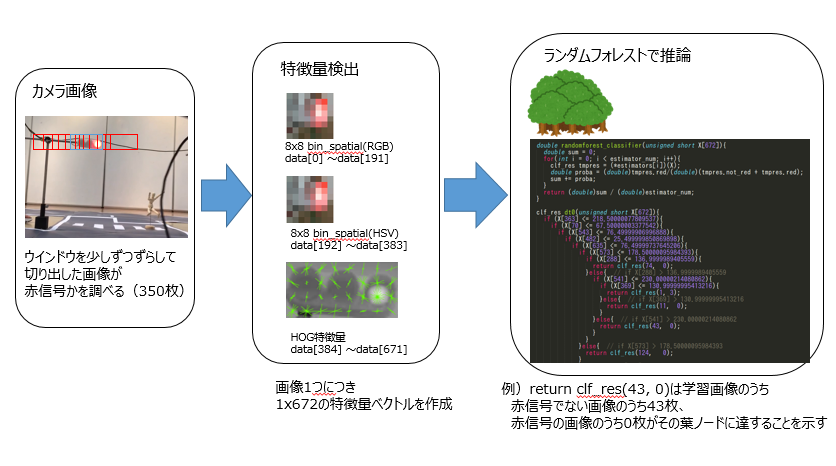
・推論
カメラから取得した画像 → ウインドウをずらしながら画像を切り取り → 切り取った画像それぞれに対して → 特徴量の抽出(画素・ヒストグラム・HOG) → RFによる認識
RFについての詳しい説明は省略しますが、いっぱい推論してくれる木が複数あって、
特徴量は1次元の配列に格納され、それぞれのif文の木をたどると(赤信号のサンプル数、赤信号以外のサンプル数)が得られます。
特徴量抽出・RF推論器のフルスクラッチ実装
②の実装において特徴量の抽出はscikit-learnとnumpyを使うことで数行で実現されている。
ライブラリのソースコードを読んでC++へ移植。scikit-learnのHOGをC++でそのまま実装すると大変な行数になった。
https://gist.github.com/lp6m/349948c876bf1b80abe06bb9bfaed37a#file-hog-cpp
RF推論器のフルスクラッチ実装は簡単で、Scikit-learnで学習したモデルのを再帰的に辿ることで、if文の木を作成できる。というかほぼ答えみたいなのがあった
stackoverflow.com
フルスクラッチ実装ができたことで、Pythonとscikit-learnを用いて学習させ、学習モデルをC++コード化してC++から利用することができるようになった。
ちなみに、本来は抽出した特徴量に対する正規化を行ってから、RFに推論させるが、正規化処理はそれぞれの特徴量の配列要素に対して独立した計算なので、RFのif文の中のしきい値を逆正規化することで、推論時の正規化処理を省略している。
学習用画像作成ツール・学習済みモデルテスト用ツールの作成
・32x64の画像を学習用に大量に作成する必要があり、撮影した動画から生成した連番画像から信号の部分を手作業で切り抜く必要があった
・自分用にツールを作ったほうが早かったのでTkinterを使って作成
Python + Tkinterで連番画像ファイルを素早く切り抜くGUI画像トリミングツール - Qiita
・これを応用して、学習済みモデルを簡単に試すためのツールも後に作成した。(左下に赤信号である確率が表示される)
わりと外乱があっても精度がでていることがわかる。

ZYBO用にHOG計算の簡単実装・HLS実装
C++で実装したリアルタイム信号検出器をZYBOのCPUで動作させると1フレームにつき1.5secほどかかってしまった。主にHOG特徴量の抽出が非常に重たかった。(sqrtしたりatanしてるので当たり前)
そこで①の実装を参考にする。ユークリッド距離の計算・ヒストグラム正規化を簡略化したりatanのテーブルをLUTに持たせることで高速化していることを参考にする。
ただ、この実装をそのままパクって使うと、SWでの計算結果と実際にFPGAにインプリメントした際のHWの計算結果が異なった。
理由はVivado HLSにおけるpragmaにあった。`#pragma HLS DEPENDENCE inter false`で配列インデックスへに対するループ依存がないことを高位合成ツールに伝えてパイプライン化を実現しているが、実際にはループ依存が存在する。
ただしこのpragmaを外すとレイテンシが大きいHWが生成されて頭を抱えた。
ふとインターンでやったラインバッファのことを思い出して、「HOG LineBuffer FPGA」で検索をかけたところ、以下の論文アーカイブ(?)に到達した。
(https://arxiv.org/ftp/arxiv/papers/1802/1802.02187.pdf)[A High-Performance HOG Extractor on FPGA]
各画素のgradientを計算する際に4近傍の画素の情報が必要になるが、ラインバッファで縦=3, 横=画像の幅=64の画素をもっておくことでループ内での画素読み込み(ブロックRAMからの読み込み)が1回で済む。
これを参考に、ラインバッファを使用したHOG特徴量抽出HLSコードを作成。レイテンシも短く、SWとHWで結果が一致するHLSコアが完成した!
■参考にしたリポジトリのHLSコード:ラインバッファなし
HOG_Zedboard/hog.cpp at master · nikkatsa7/HOG_Zedboard · GitHub
■実装したHLSコード:ラインバッファあり
ImageDetectionHW/main.cpp at master · lp6m/ImageDetectionHW · GitHub
比較すると、画素情報が格納されている`image_buffer`へのアクセス(=ブロックRAMへのアクセス)がループ内で1回で済んでいることがわかる。
↓これはなんかHLS実装してたときのメモ

FPGAへの実装・Linuxからの利用
作成したHLS IPコアは1枚の画像のHOG特徴量を計算してくれるコアなので、ウインドウが300個あるときは300回HLS IPコアを実行する必要がある。
Vivado上でHLS IPを4つならべて、4つの画像のHOG特徴量を同時に計算してくれるようにした。
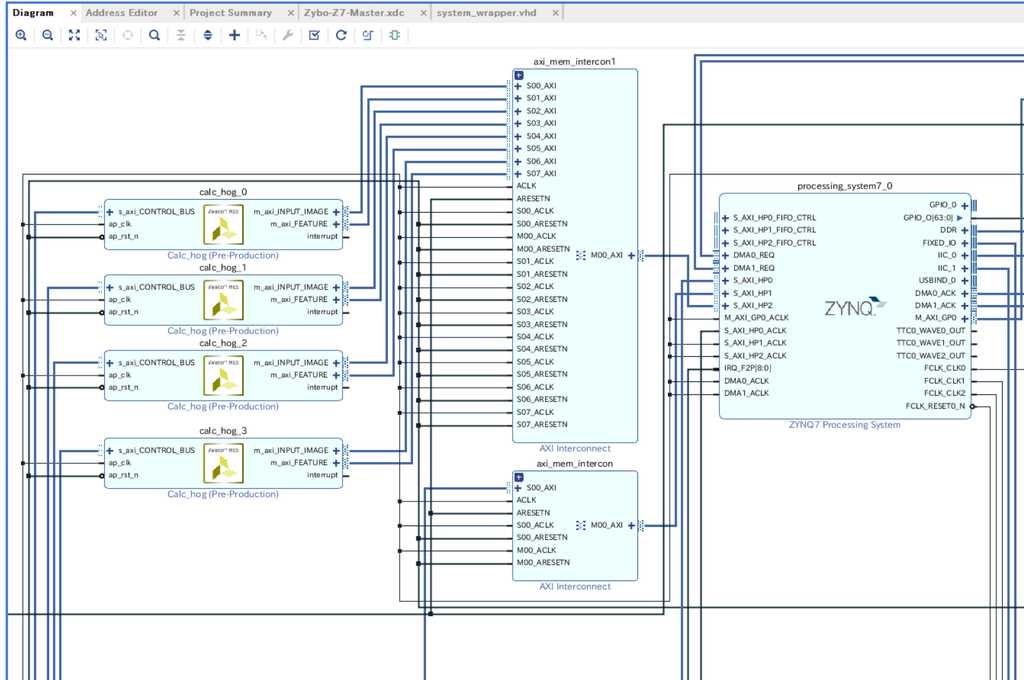
LinuxからUIOを用いてHLS IPを利用するにあたっては①の実装を丸パクリさせていただいた。ありがとうございます。。。
結果的にSWで計算するよりも5,6倍高速になり、ZYBO上で12〜15fpsの信号検出を達成した。FPGAを活用したといえる(?)状態にはなった。
完成したものを友人に投げて、自動運転システムに組み込んでもらった。
おわりに
なんとか1ヶ月でFPGAを活用した信号検出プログラムを作成することができた。
画像認識や機械学習も初めてで、HLSツールもまともに使ったことがなかったのでなかなか頑張ったとは思っている。
開発中は、コースの整備やロボット本体の作成などに予想外に時間を取られた。
開発記には書いてないが、OpenCVを使ってカメラ画像を取得するとCPU使用率が非常に高くなったのでV4L2 APIをゴリゴリ叩いてカメラ画像を取得したりしている。
そういった絶妙なハマりポイントに陥りまくった。
手元のPCでは余裕で30fpsで信号を検出できるのにZYBOで実行したら1.5fpsとかになったりして、エッジデバイスの弱さを実感した。
通信プロトコルがAXI4/AXI4-LiteなのでCPUが通信を制御する必要があり、結局SW/HW間の通信がボトルネックになっているのが残念。
AXI-Streamプロトコルを使ってDMA転送することでもっとCPUの負荷を減らせるとは思う。DMAをLinuxから使えるようになりたい。
使えるようになったらブログにまとめたいと思う。
まだまだ課題もあるが、コンテストのおかげで色々と勉強することができた。
Twitter等で助言を頂いた方々、ありがとうございました。
FPGAデザインコンペ@FPT2018優勝しました🏆
— lp6m (@lp6m2) 2018年12月12日
自分の担当は信号検出のHW実装でした
やり残したこともたくさんあるので次回も頑張ります(?)
ありがとうございました pic.twitter.com/spdVpjta5d
Ubuntu on ZYBO Z7-20からFPGAで画像処理したPCam 5Cの映像をV4L2デバイスの映像として取得したい(失敗)
タイトルが随分ながくなってしまった。
前回Ubuntu on ZYBO Z7-20からPCam 5Cの映像を取得したい(成功) - lp6m’s blogでは、PCam 5CカメラをV4L2デバイスとして認識させ、画像を取得することができた。
せっかくMIPI経由でFPGA側に画像の信号があるので、HLSコアを用いて画像処理することはできないかと思った。
FPGAで画像処理しているカメラの画像がV4L2デバイスとしてOSに認識されて、簡単に画像取得できるとたぶんかなり嬉しい。
途中まで成功して、途中からは失敗したのでとりあえずログをまとめる。
やりたいこと
やりたいことの概略図は以下のようになる。
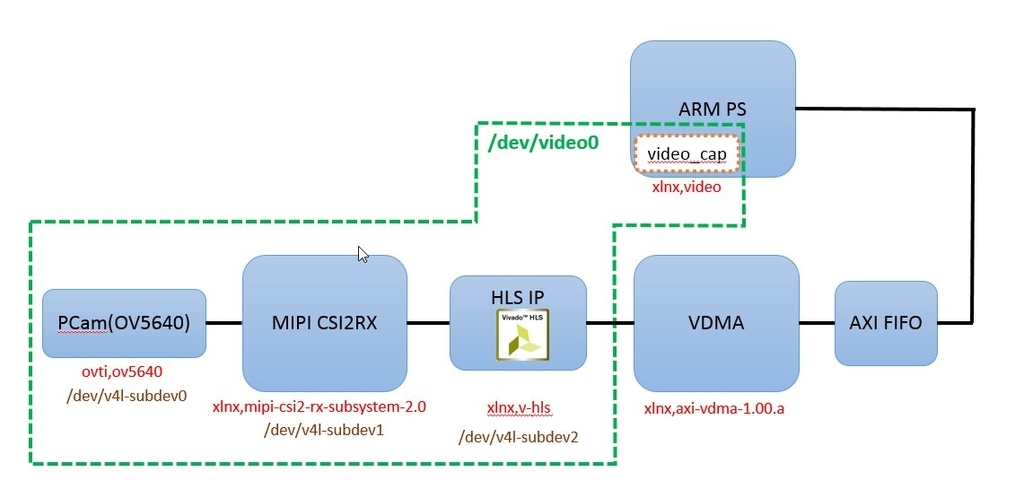
元々のプロジェクトのFrame Buffer Write IPをVDMAに差し替えて、HLSコアを挿入するだけ。
元々のプロジェクトではYUYV形式でAXI4-StreamのDataWidthは16bit。
とりあえず情報を8bitに落とすHLSコアをつくって、1画素あたり8bitの情報を転送したい。
元のVivadoプロジェクトの確認
※元プロジェクトにはMIPI CSI2RX Subsystem IPが含まれており、LogiCore IPライセンスがないと合成やビットストリーム出力をすることができません。
1. DigilentのgithubリポジトリGitHub - Digilent/Zybo-Z7-20-base-linuxからgit cloneする。
repo/vivado-libraryがgit submoduleになっている。回路で使用されているコアが別リポジトリに含まれており必要なので、以下コマンドでサブモジュールごとcloneする
git clone --recursive https://github.com/Digilent/Zybo-Z7-20-base-linux
Tools->Report->Report IP StatusからIP情報を更新、合成を行ってビットストリーム生成に成功することを確認。
Frame Buffer Write IPをVDMA IPに差し替え(ここまでは成功)
Vivado側の作業
元の回路にはFrame Buffer Write IPとよばれるIPが使われている。決まったビデオフォーマットにのSS2M(AXI4-Stream -> Memory Mapped)書き込みに特化したIPらしい。
Frame Buffer Write IPのフォーマットを変更してもDataWidthが8bitのフォーマットはなかったので、これをVDMAに差し替えて好きなデータ幅の転送ができるようにする。
とりあえずHLSコアを入れずに、VDMAに差し替えるだけを行う。
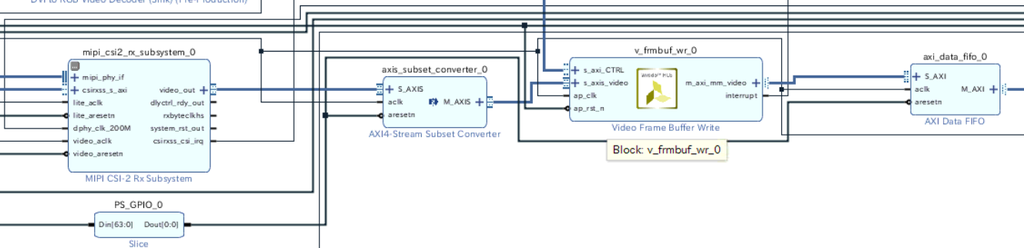
axis_subset_converter_0とv_frmbuf_wr_0を削除して、VDMAを挿入
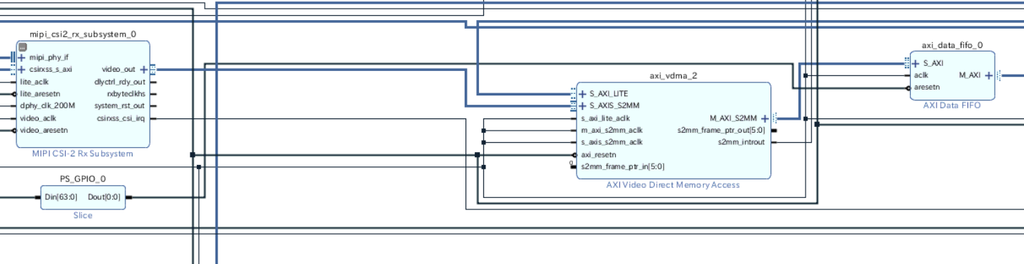
この状態で合成・ビットストリーム生成を行う。
Export Hardwareを行い、Petalinuxプロジェクトにコピー。
Petalinuxプロジェクト側の作業
petalinux-config --get-hw-description <.hdfのあるディレクトリ>
HW情報をpetalinuxに読みこませる。
次にデバイスツリー(system_user.dtsi)を書き換える。FrameBuffer Write IPに対応する部分をコメントアウトして、amba_pl/video_capで指定しているDMAをFrameBuffer Write IPからVDMA IPに変更。
オリジナルとのdiffを載せておく。
10c10
< bootargs = "console=ttyPS0,115200 earlyprintk uio_pdrv_genirq.of_id=generic-uio root=/dev/mmcblk0p2 rw rootwait";
---
> bootargs = "console=ttyPS0,115200 earlyprintk uio_pdrv_genirq.of_id=generic-uio";
264c264
< /*&v_frmbuf_wr_0 {
---
> &v_frmbuf_wr_0 {
273c273
< };*/
---
> };
278c278
< dmas = <&axi_vdma_2 0>;
---
> dmas = <&v_frmbuf_wr_0 0>;
335,336d334
<
<これでPetalinuxのプロジェクトをビルドする。
petalinux-build
ここまでやってpetalinux-buildすると以前作成したカメラ画像取得プログラムが正常に動作した。
HLSコアの作成
YUYV16bitでは、1画素の情報は「YとU」あるいは「YとV」である(UとVは2画素に1つしか情報がなく、軽量)。いずれの場合もはじめの8bitを取り出す、すなわちYの値だけをとりだすコアを作成する。
Vivado HLSで1画素ずつの処理を行うサンプルが以下で公開されているので、それを参考にさせていただく。
github.com
yuyvyというモジュールを作成した。また、axiliteプロトコルでしきい値を設定するといったことも将来的に行いたいので、char型のしきい値を入力として受けるようにした。
作成したコアのコードは以下リンク。
Extract Y 8bit data from YUYV 16bit data. · GitHub
実際に計算を行っているのは59行目の以下の部分だけ。YUYVからYの値を取り出して、valとのmaxを結果とする。特に意味はない。
コードの大部分はTLASTやTUSERなどの信号を扱うためのコード。解説されると簡単だけと自分で書くのは難しい・・
axis_writer.data = std::max((int)((axis_reader.data & 0xFF00) >> 8), (int)val);
高位合成の結果は以下の通りになった。まだ未熟で見方がわかってないが、特に問題はないらしい。。?
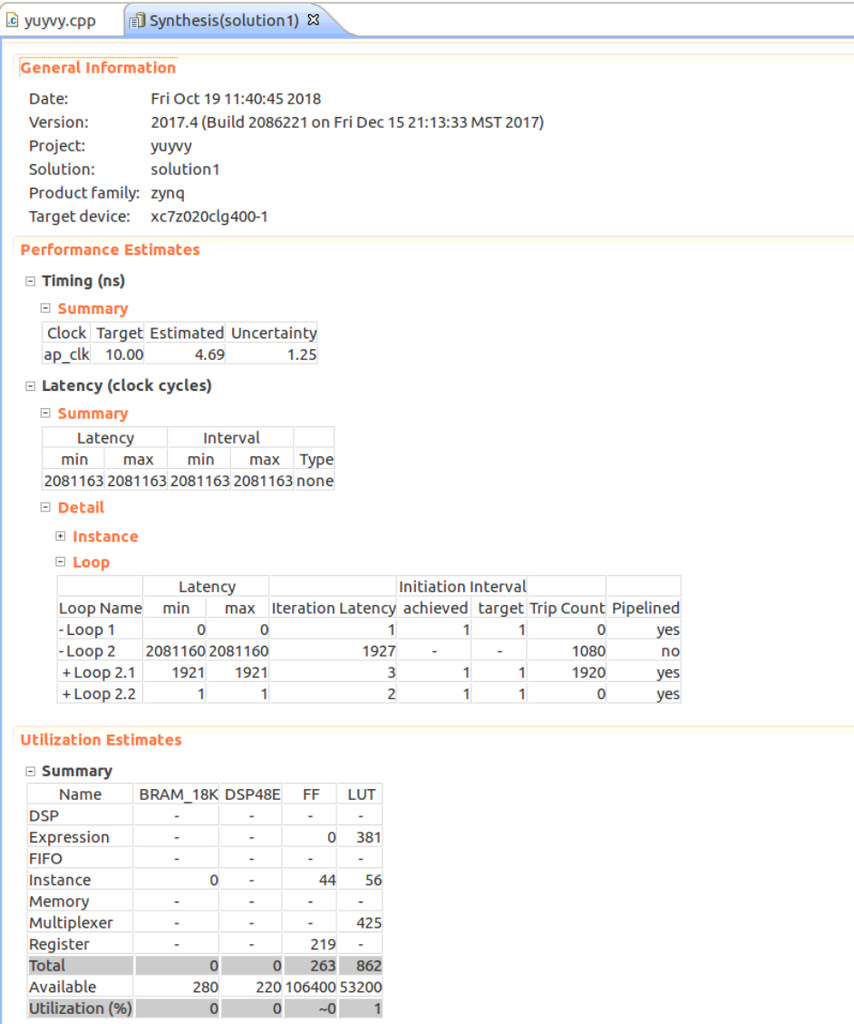
Export RTLでIPとしてエクスポートを行った。
HLSコアを回路に挿入
Vivadoプロジェクトに戻り、IP CatalogにエクスポートしたHLS IPコアを追加する。
回路にHLS IPコアを挿入。
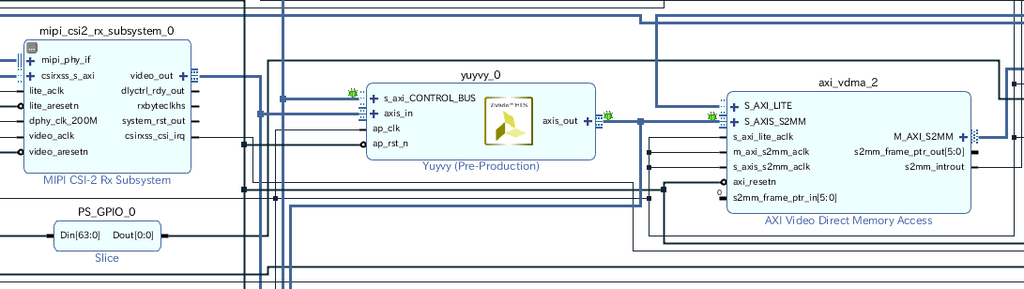
HLSコアはs_axiliteプロトコルの入力があるので、メモリマップする必要がある。Address Editorでアドレスを割り当てる。
とりあえず、0x43c80000から64K割り当てた。
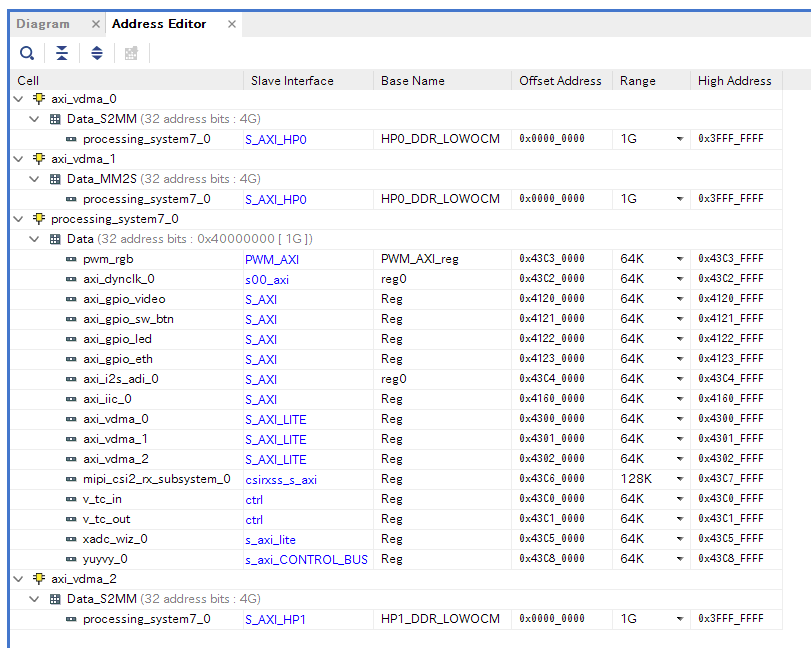
この状態で合成・ビットストリーム生成を行う。
Export Hardwareを行い、Petalinuxプロジェクトにコピー。
Petalinuxプロジェクトの編集
先ほどと同様にpetalinux-config --get-hw-description <ディレクトリ>で新しい回路情報をプロジェクトにロードする。
ここから、Petalinuxプロジェクト側でデバイスツリーを書き換える。
Digilent Linux Kernelの話
注意しなければならないことが1つある。PetalinuxではLinuxカーネルの参照をgitリポジトリにすることができるのだが、
元のPetalinuxプロジェクトはDigilent Linux Kernelリポジトリの最新版ではなく、途中のコミットのものを参照している。
これを最新のものを参照するようにpetalinux-configで書き換えてしまうと動かなかった。
例えばMIPI CSI2RX Subsystemのデバドラは最新版と使用しているPetalinuxが参照しているバージョンを見比べてみる。 旧版ではデバイスツリーのreset-gpioプロパティで指定したピンのリセットをxcsi2rxss_start_stream関数で行うが、最新版では行わない。
サンプルプロジェクトではMIPI CSI2RXSSのvideo_aresetnピンはGPIOに接続されており、これがリセットされないことでMIPI CSI2RXSSのSoft Resetがタイムアウトしてしまう。
(最新版のデバドラを使う場合は他の方法でvideo_aresetnをリセットしないといけなくなった)
まあ要は元々のままにしておけばいいのだけど、自分でカーネルをフォークする場合などは要注意。これで3日溶かした。
V4L2デバイスの話
HLSコアをV4L2のサブデバイスとして登録してくれるデバイスドライバxilinx-hls.cがDigilent Linux Kernelには存在する。
ソースコード:
linux-digilent/xilinx-hls.c at 1496c680c6df2e3911feed13aa9663a851bf30e9 · Digilent/linux-digilent · GitHub
ドキュメント:
linux-digilent/xlnx,v-hls.txt at 1496c680c6df2e3911feed13aa9663a851bf30e9 · Digilent/linux-digilent · GitHub
これらを参考にして、デバイスツリーを編集する。
はじめの「やりたいこと」でも表している図の説明になるが、カメラ+画像処理がV4L2デバイス/dev/video0として認識されるのは、大体以下のような仕組み(のはずと理解したつもり・・・)
- video_capが「xlnx,video」ドライバによって/dev/video0として認識される
- xlnx,videoドライバはデバイスツリーで指定されている「エンドポイント」を辿って、サブデバイスを探す
- PCam 5C、HLS IP、MIPI CSI2RX IPは各デバイスドライバによってV4L2サブデバイスとして登録される
(各デバイスドライバは必要に応じてIPコアのリセットなどを適切に行ってくれる。ユーザアプリケーションはioctl()サービスコールを用いてドライバを呼び出すことができる)
デバイスツリーの編集
デバイスツリーの編集
そのまえに、Petalinuxで自動的に生成されるデバイスツリーをみる。(これはおそらくXilinx SDKで自動生成できるものと同じ)
petalinux-config --get-hw-descriptionでは回路に対応するデバイスツリーはなぜか生成されない。
とりあえずエラーがでてもいいので、petalinux-buildコマンドを叩くと回路に対応するデバイスツリーが更新される。
生成されるデバイスツリーは
自動生成されたpl.dtsiを参考程度に貼っておく。
Dropbox - File Deleted
ユーザが記述するデバイスツリーsystem_user.dtsiはこの自動生成されたデバイスツリーに情報を付加・補完する形になっている。
それぞれのサブデバイスの接続情報がデバイスツリーにかかれているので、これらを編集する。
編集したデバイスツリーは以下。
Dropbox - File Deleted
オリジナルのデバイスツリーとのdiffは以下の通り。
245c245
< remote-endpoint = <&hls0_in>;
---
> remote-endpoint = <&vcap_in>;
264c264
< /*&v_frmbuf_wr_0 {
---
> &v_frmbuf_wr_0 {
273c273
< };*/
---
> };
278c278
< dmas = <&axi_vdma_2 0>;
---
> dmas = <&v_frmbuf_wr_0 0>;
289,311d288
< remote-endpoint = <&hls0_out>;
< };
< };
< };
< };
< };
<
< yuyvy_0: yuyvy@43c80000 {
< compatible = "xlnx,v-hls";
< reg = <0x43c80000 0x0024>, <0x43c80024 0xFFDC>;
< clocks = <&clkc 15>;
<
< ports {
< #address-cells = <1>;
< #size-cells = <0>;
<
< port@0 {
< reg = <0>;
<
< xlnx,video-format = <XVIP_VF_YUV_422>;
< xlnx,video-width = <8>;
<
< hls0_in: endpoint {
315,324d291
< port@1 {
< reg = <1>;
<
< xlnx,video-format = <XVIP_VF_MONO_SENSOR>;
< xlnx,video-width = <8>;
<
< hls0_out: endpoint {
< remote-endpoint = <&vcap_in>;
< };
< };
325a293
> };
367,368d334
<
< HLS IPが1画素8bitのデータを出力する。これに相当するvideo-formatの値はXVIP_VF_MONO_SENSORのようだ。(UG934, 9ページ参照)
yuyvy_0: yuyvy@43c80000内のreg = <0x43c80000 0x0024>, <0x43c80024 0xFFDC>の意味がわからない。
ドキュメントによると
- reg: Physical base address and length of the registers sets for the device.
The HLS core has two registers sets, the first one contains the core
standard registers and the second one contains the custom user registers.
らしいけど、standard registerとcustom user registerってなんのことだろう・・?とりあえずデフォルトの0x0024の範囲をstandard registerにしたけど。
HLS IPには64K割り当てたのでとりあえず合計0x100000になるようにした。
カーネルコンフィグの変更
元々のpetalinuxプロジェクトではHLS IPに対応するデバイスドライバが有効になっていない。
petalinux-config -c kernel
でカーネルコンフィグを表示して、xlnx,hlsを有効(Build-In)にする。
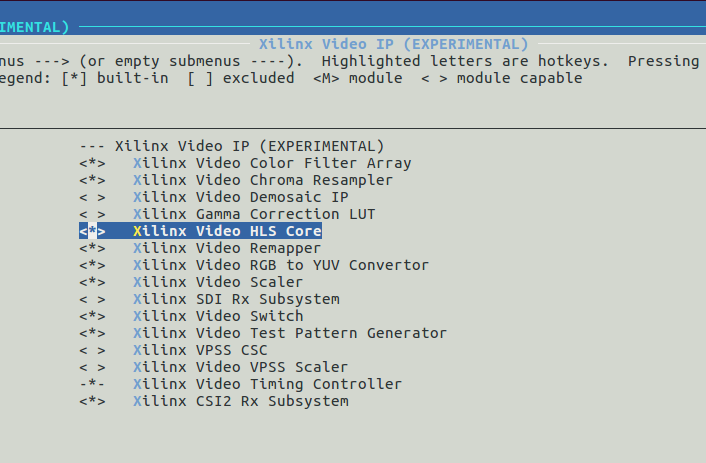
これでPetalinux側の作業も終わり。プロジェクトのビルドおよびFSBLとU-BOOTのビルドを行う。
petalinux-build petalinux-build -c fsbl petalinux-build -c u-boot
BOOT.BINの作成
以下コマンドでBOOT.BINを作成する。
petalinux-package --boot --fsbl images/linux/zynq_fsbl.elf --fpga <bitファイルのパス> --u-boot --force
起動およびデバイス認識の確認
これまでどおりSDカードのFATでフォーマットした第1パーティションにimage.ubとBOOT.BINを,第2パーティションにUbuntuのrootfsを入れる。
PCam 5Cを接続し、/dev/media0と/dev/video0が見えていればとりあえずデバイスドライバが正常にデバイスを登録できていることが確認できる。。
Ubuntuにはsudo apt-get install v4l-utilsでV4L-Utilsをインストールしておく。
ログイン後、sudo su -コマンドでスーパユーザに切り替えてから、V4L2サブデバイスのフォーマットの設定を行う。(本家と同じコマンド)
root@arm:~# width=1920 height=1080 rate=15 media-ctl -d /dev/media0 -V '"ov5640 2-003c":0 [fmt:UYVY/'"$width"x"$height"'@1/'"$rate"' field:none]' media-ctl -d /dev/media0 -V '"43c60000.mipi_csi2_rx_subsystem":0 [fmt:UYVY/'"$width"x"$height"' field:none]'
このコマンドで、デバイスツリーでフォーマットを指定していていなかった情報をセットしている。
V4L2デバイスが正しく認識、かつ正しくパラメータがセットされていることを以下のコマンドで確認する。
root@arm:~# media-ctl -p /dev/video0
Media controller API version 4.9.0
Media device information
------------------------
driver xilinx-video
model Xilinx Video Composite Device
serial
bus info
hw revision 0x0
driver version 4.9.0
Device topology
- entity 1: video_cap output 0 (1 pad, 1 link)
type Node subtype V4L flags 0
device node name /dev/video0
pad0: Sink
<- "43c80000.yuyvy":1 [ENABLED]
- entity 5: ov5640 2-003c (1 pad, 1 link)
type V4L2 subdev subtype Sensor flags 0
device node name /dev/v4l-subdev0
pad0: Source
[fmt:UYVY/1920x1080 field:none]
-> "43c60000.mipi_csi2_rx_subsystem":1 [ENABLED]
- entity 7: 43c80000.yuyvy (2 pads, 2 links)
type V4L2 subdev subtype Unknown flags 0
device node name /dev/v4l-subdev1
pad0: Sink
[fmt:UYVY/1920x1080 field:none]
<- "43c60000.mipi_csi2_rx_subsystem":0 [ENABLED]
pad1: Source
[fmt:Y8/1920x1080 field:none]
-> "video_cap output 0":0 [ENABLED]
- entity 10: 43c60000.mipi_csi2_rx_subsystem (2 pads, 2 links)
type V4L2 subdev subtype Unknown flags 0
device node name /dev/v4l-subdev2
pad0: Source
[fmt:UYVY/1920x1080 field:none]
-> "43c80000.yuyvy":0 [ENABLED]
pad1: Sink
[fmt:UYVY/1920x1080 field:none]
<- "ov5640 2-003c":0 [ENABLED]登録は成功しているようだ。特にHLS IPである43c80000.yuyvyのSourceのフォーマットは[fmt:Y8]となっており、1画素のデータが8bitのデータが出力されるということが登録されている。
カメラ撮影プログラムの修正
カメラ撮影プログラムは以前作成したプログラムを元に作成する。
HLSコアにはs_axilite経由の入力値があるので、これをセットする必要がある。HLSコアは先ほどのコマンドで/dev/v4l-subdev1に認識されていることが確認できた。
VIvadoHLSでExport RTLを行うと、IPコアのためのドライバが出力される。(/solution1/impl/ip/drivers/yuyv_v1_0/src)
この中にあるxyuyv_hw.hは以下の通り。
// CONTROL_BUS // 0x00 : reserved // 0x04 : reserved // 0x08 : reserved // 0x0c : reserved // 0x10 : Data signal of val_r // bit 7~0 - val_r[7:0] (Read/Write) // others - reserved // 0x14 : reserved // (SC = Self Clear, COR = Clear on Read, TOW = Toggle on Write, COH = Clear on Handshake) #define XYUYVY_CONTROL_BUS_ADDR_VAL_R_DATA 0x10 #define XYUYVY_CONTROL_BUS_BITS_VAL_R_DATA 8
ここから、物理アドレスの0x43c80000+オフセット0x10の位置に値を書き込めば、HLSコアの入力値valを設定できるということがわかる。
嬉しいことに、HLS IPのデバドラにはs_axilite経由の値をサービスコールを用いて書き込む機能がある。
xilinx-hls-common.hやxilinx-vip.hを含めてデバイスドライバのソースコードを読んだところ。
struct buffer_addr_struct{ void *start[FMT_NUM_PLANES]; size_t length[FMT_NUM_PLANES]; } *buffers; struct xilinx_axi_hls_register { __u32 offset; __u32 value; }; struct xilinx_axi_hls_registers { __u32 num_regs; struct xilinx_axi_hls_register *regs; }; #define XILINX_AXI_HLS_READ _IOWR('V', BASE_VIDIOC_PRIVATE+0, struct xilinx_axi_hls_registers) #define XILINX_AXI_HLS_WRITE _IOW('V', BASE_VIDIOC_PRIVATE+1, struct xilinx_axi_hls_registers)
を記述しておき、
xilinx_axi_hls_register reg[1]; reg[0].offset = 0x10; reg[0].value = 255; xilinx_axi_hls_registers regs; regs.num_regs = 1; regs.regs = reg; int fd2; fd2 = open("/dev/v4l-subdev1", O_RDWR, 0); if (fd2 == -1){ std::cout << "Failed to open subvideo device." << std::endl; return 1; } if (-1 == xioctl(fd2, XILINX_AXI_HLS_WRITE, ®s)){ std::cout << "Failed to set param via s_axilite" << std::endl; return 1; }
を実行すれば値を書き込めそうだということがわかった。reg[0].offset = 0x10;の値は先程のxyuyv_hw.hを参考に設定した。
また、/dev/video0に設定するフォーマットは1画素8bitのフォーマットなので、
fmt.fmt.pix_mp.pixelformat = V4L2_PIX_FMT_GREY;
に変更する。
最終的に完成したプログラムのコードを以下に示す。
Dropbox - File Deleted
実行・・失敗
実行してみたが、途中で止まってしまった。実行ログは以下の通り。
root@arm:/home/ubuntu# ./a.out waiting in xioctl() waiting in xioctl() bus_info : platform:video_cap:0 card : video_cap output 0 driver : xilinx-vipp version : 264448 waiting in xioctl() waiting in xioctl() reqbuf.count : 3 waiting in xioctl() buf.length : 1 buf.m.offset : 3196044192 buf.m.planes[j].length : 2073600 buffers[i].start[j] : 0xb6a9a000 waiting in xioctl() buf.length : 1 buf.m.offset : 3196044192 buf.m.planes[j].length : 2073600 buffers[i].start[j] : 0xb689f000 waiting in xioctl() buf.length : 1 buf.m.offset : 3196044192 buf.m.planes[j].length : 2073600 buffers[i].start[j] : 0xb66a4000 waiting in xioctl() waiting in xioctl()
具体的にはxioctl(fd, VIDIOC_STREAMON, &buf.type))を実行してカメラのキャプチャをスタートしようとすると、サービスコール呼び出しの実行がおわらず、待機状態になる。
バッファの確保はできているようだ。
わからないこと
- なぜ取得できなかったのか・・
いろいろ理由を考えているけど、わからない。
- 前述のyuyvy_0: yuyvy@43c80000内のreg = <0x43c80000 0x0024>, <0x43c80024 0xFFDC>はどのように設定するのが正しいのか
この設定とカメラ取得プログラムのreg[0].offset = 0x10;は関係ありそう。デバイスドライバをもう少しきちんと読もう。
- HLSコアはap_ctrl_noneになっているが、axilite経由の入力の値がセットされていない場合はどのように動作するのか?
デフォルト値(intなら0とか)が使用されるのかなと思っている。入力の値がセットされていないから計算が実行されない、なんていうことは多分ないと思っている。
(もしそうなら、カメラ取得プログラムで正しく入力値valが設定されていないせいでHLSの出力がでていない、というのも原因として考えられる。)
そうでないなら、axilite経由の値をうまくセットできていなかったとしても何らかの出力は出るのではないか・・?
これに関してはTwitter上でできるという話を聞いたが、やってみたが上手くいかない・・
- タイミングの問題が原因?
これは見方をまだ理解していない。赤字なので何かヤバそう・間に合っていないとは思う。ただ、回路を変更する前から赤字はあった。値の変化はまだ確認していない。

ブログが非常に長くなってしまった。何か原因として考えられることがあればご教示願います・・・