DNNDK + Ultra96でYOLOv3物体認識onFPGA (その1・FPGA向けデプロイまで)
- はじめに
- 実行環境
- DNNDKのダウンロード・インストール
- Tutorialのダウンロード・とりあえず実行
- darknet(YOLO)で自前のデータを学習
- 自前で学習した重みとネットワークをFPGA向けにデプロイ
はじめに
Deephiという中国の会社がXilinxに買収?されてXilinxからDNNDKとよばれるFPGAにDNNを簡単に実装するフレームワークがリリースされています。

今回はコレをやってみます。機械学習に関する詳しいことを全く理解していなくても適当にコマンドを叩くだけで物体認識onFPGAができてしまいそうです。
https://github.com/Xilinx/Edge-AI-Platform-Tutorials/tree/master/docs/Darknet-Caffe-Conversiongithub.com
実行環境
- Ubuntu16.04 LTS
- GeForce GTX980
- OpenCV 3.3.0
- CUDA 9.0
- CUDNN 7.0.5
UbuntuとCUDAとCUDNNのバージョンはDNNDKフレームワークがサポートするものが限られているので注意。
nvidiaのドライバのせいでログインループに陥ったりして環境構築をするのが大変だった。
自分の環境ではnvidiaドライバはnvidia-418がインストールされていて安定している。(nvidia-430やnvidia-387でログインループに陥った)
DNNDKのダウンロード・インストール
- xlnx_dnndk_v2.08_190201.tar.gz https://www.xilinx.com/member/forms/download/dnndk-eula-xef.html?filename=xlnx_dnndk_v2.08_190201.tar.gz
$tar -xvf xlnx_dnndk_v2.08_190201.tar.gz $cd xilinx_dnndk_v2.08/host_x86 $sudo ./install.sh Ultra96 Inspect system enviroment... [system version] No LSB modules are available. Description: Ubuntu 16.04.6 LTS 16.04 [CUDA version] 9.0.176 [CUDNN version] 7.0.5 Begin to install DeePhi DNNDK tools on host ... Complete installation successfully.
これでDNNモデルを量子化するdecentコマンドや量子化済みモデルをコンパイルするdnnc-dpu1.3.0コマンドが使用できるようになる。
このタイミングで対象ボードを指定するので、Ultra96向けに量子化・コンパイルが行われるのだろう。
Tutorialのダウンロード・とりあえず実行
一旦、チュートリアル通りに実行してみます。
$git clone https://github.com/Xilinx/Edge-AI-Platform-Tutorials
チュートリアルのprerequisitesにも書いてあるようにYOLOの学習済みの重みをダウンロードする必要があります。
$cd Edge-AI-Platform-Tutorials/docs/Darknet-Caffe-Conversion/ $wget https://pjreddie.com/media/files/yolov3.weights $mv yolov3.weights ./example_yolov3/0_model_darknet/ $bash -v tutorial.sh
これでいくつかの圧縮ファイルが解凍されて、必要なプログラムがmakeされます。
おそらく初めて実行すると環境が不十分でdarknetやcaffeのmakeがコケるので、適宜必要なものをインストールしてmakeが通るようにします。
何度も試行錯誤するときにmake cleanされるのはめんどくさいのでtutorial.shのmake cleanをコメントアウトして行いました。
UG1327ではcaffeのビルドに以下が必要と書かれています。参考程度に。
その他にdos2unixやprotobufとかもインストールする必要がありました。すべては覚えていません、スミマセン。
apt-get install -y --force-yes build-essential autoconf libtool libopenblasdev libgflags-dev libgoogle-glog-dev libopencv-dev protobuf-compiler libleveldbdev liblmdb-dev libhdf5-dev libsnappy-dev libboost-all-dev libssl-dev
※私の環境では 『.build_release/lib/libcaffe.so: `cvLoadImage' に対する定義されていない参照です』等でcaffeのビルドに失敗します。
これを回避するためcaffe-master/Makefileの421行目を書き換えました。
USE_PKG_CONFIG ?= 1 #0から変更
darknet(YOLO)で自前のデータを学習
今回は、とりあえずこの2つの障害物を認識してもらうことにします。認識精度などは置いといてとりあえず実行したかったので学習画像は各100枚程度にしました。
学習データの用意
こちらの記事を参考にさせていただいて、自前データの学習を行います。
チュートリアルをクローンしてきた時についてきたdarknet_originを使ってもいいのですが、今回はオリジナルのリポジトリからcloneしたほうで学習を行いました。
YOLOオリジナルデータの学習 - Take’s diary
Yolo v3を用いて自前のデータを学習させる + Yolo v3 & opencv のインストール方法付き(Ubuntu 16.04, Opencv 3.3, Conda) - Qiita
1つめの記事にしたがって、yolov3-voc.cfgのclasses, filtersを3箇所書き換えました。(今回はclasses=2, filters=21)
2つめの記事にしたがって画像のアノテーションを行い、train.txt, test.txtを作成し、obj.data, obj.namesファイルを正しく記述します。
学習を実行
記事通りにデータを用意すれば、以下のコマンドで学習が始まります。
./darknet detector train cfg/obj.data cfg/yolov3-voc.cfg darknet53.conv.74
GPUのメモリが足りずに以下のようなエラーで落ちることがあります。
CUDA Error: out of memory darknet: ./src/cuda.c:36: check_error: Assertion `0' failed.
これはcfg/yolov3-voc.cfgの頭のsubdivisionsを16に変更することで回避しました。参考:darknetでYoLoV3マルチクラス学習 - ロボット、電子工作、IoT、AIなどの開発記録
2時間くらい放置して2000回程度回しました。
2101: 0.069695, 0.069695 avg, 0.001000 rate, 3.346575 seconds, 33616 images
avgの前の値が小さいほどいい感じに学習ができているということだそうです。今回は早く試したいのでとりあえずこの辺で学習は終了。
(重みは100回ごと?に保存されるようです)
学習済みモデルの確認
参考の記事通りに設定を書いていればbackupディレクトリ内に学習済みの重みが保存されているので、これを使って学習がうまくいったか確認します。
./darknet detector test cfg/obj.data cfg/yolov3-voc.cfg backup/yolov3-voc.backup test.jpg -thresh 0.1
これで先ほどの画像が結果として得られました。とりあえずはうまく行ってるようです。簡単にできてしまって凄い。
自前で学習した重みとネットワークをFPGA向けにデプロイ
基本的にはtutorial.shそのままでいいのですが、何故か自動化されて欲しいところが自動化されていなかったので簡単な追記を行いました。
修正したものはここで公開しています。
github.com
tutorial.shのワークフローを簡単に図にしたものを以下に示します。
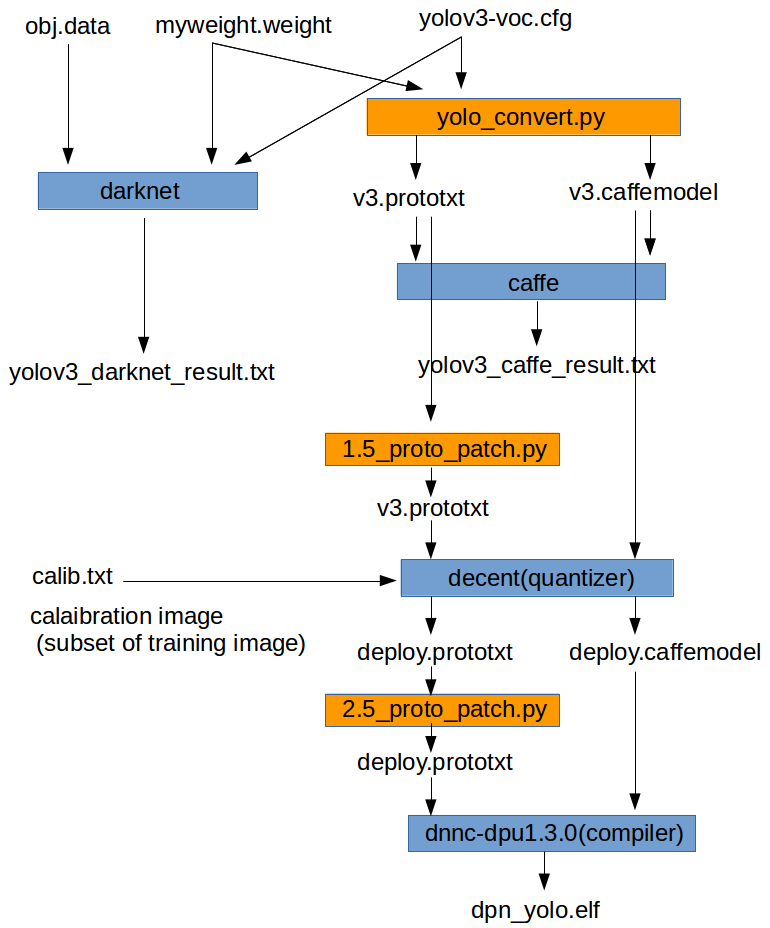
オレンジ色の1.5_proto_patch.pyと2.5_proto_patch.pyは今回私が作成した簡単なコードです。
両方とも、その前のプロセスで出力されたDNNのモデル情報のテキストファイルを次のプロセスに渡すために、一部コメントアウトしたり情報を追加するものになっています。
ドキュメントでは自分で手作業で編集するようになっており、元々のtutorial.shでは、編集済みのファイルをコピーするようになっています。。
これだとモデル情報を変更した際に自動化できないので、雑なコードを記述しました。
自前で学習した重み・ネットワークをデプロイするために修正した箇所は以下の通りです。
0_convert.sh
学習に使用したモデルのcfgファイルと、学習済みの重みを手作業でコピーしておきます。
これらを読み込むように2つの引数を書き換えます。
python ../yolo_convert.py 0_model_darknet/yolov3-voc.cfg 0_model_darknet/myweight.weights 1_model_caffe/v3.prototxt 1_model_caffe/v3.caffemodel
0_test_darknet.sh
同様に自分のモデルと重み、検出クラスのファイルを使って検証を行うように書き換えます。
../darknet_origin/darknet detector valid 5_file_for_test/obj.data 0_model_darknet/yolov3-voc.cfg 0_model_darknet/myweight.weights -out yolov3_results_ cat results/yolov3_results_* >> 5_file_for_test/yolov3_darknet_result.txt cat results/yolov3_results_* >> 5_file_for_test/yolov3_darknet_result.txt
学習時に使用したobj.namesを5_file_for_testディレクトリ内にコピーしておくことも忘れずに。
obj.data
obj.dataは学習時に使用したものから書き換えました。検証を行う対象の画像を1つにするためです。
classes = 2 valid = example_yolov3/5_file_for_test/image.txt names = example_yolov3/5_file_for_test/obj.names
ここで検証対象の画像ファイルのパスが書かれているテキストファイルがimage.txtであると指定されています。
image.txtの中身はtest.jpgなので書き換える必要なし。test.jpgを自分が検証に使用したい画像に差し替えます。
1_test_caffe.sh
クラス数を自分が学習したクラス数に書き換えます。(今回は2)
これをしないと出力されるdetection.jpgに枠が無数に表示されておかしなことになった。
./../caffe-master/build/examples/yolo/yolov3_detect.bin 1_model_caffe/v3.prototxt \ 1_model_caffe/v3.caffemodel \ 5_file_for_test/image.txt \ -out_file 5_file_for_test/yolov3_caffe_result.txt \ -confidence_threshold 0.005 \ -classes 2 \ -anchorCnt 3
5_file_for_test/calib.txt
何をやっているのかは正直よくわかっていませんが、2_quantize.shで量子化を行う際にキャリブレーションという作業が行われるようです。
チュートリアルには
The 5_file_for_test/calib_data folder contains some images from the COCO dataset, to be used for the calibration process.
とかいてあるので、学習データのサブセットのファイル名を記述しておけばよいようです。
フォーマットはファイル名 1で、1には特に意味がないらしいです。
学習時に作成したtrain.txtのデータを整形してcalib.txtとしてあげればOKです。
指定したパスに学習画像もコピーしてあげる。
1.5_proto_patch.py, 2.5_proto_patch.py
0_convert.sh, 2_quantize.shで生成されたモデル情報は次プロセスまでに手作業で書き換える必要があります。
先述の通りなぜか元々は編集済みのものをコピーして書き換えるようになっていましたが、汎用性がないので適当にコードを書きました。
コードはここにあります。Edge-AI-Platform-Tutorials/docs/Darknet-Caffe-Conversion/example_yolov3 at master · lp6m/Edge-AI-Platform-Tutorials · GitHub
tutorial.sh
caffe-masterをビルドした後にcd ..抜けのミスがあるのでそれを追記。
1.5_proto_patch.pyと2.5_proto_patch.pyを途中で呼び出すように修正。
ここには#check the environment以降をそのまま貼り付けておきます。
#check the environment python -c "import caffe; print caffe.__file__" cd .. ############################################################################ # Section 3.0 ############################################################################ cd example_yolov3/ rm results/* rm 5_file_for_test/yolov3_*_result.txt # step 0: Darknet to Caffe conversion bash -v 0_convert.sh # step 1: test Darknet and Caffe YOLOv3 models bash -v 0_test_darknet.sh bash -v 1_test_caffe.sh # step 2: quantize YOLOv3 Caffe model cp 1_model_caffe/v3.caffemodel ./2_model_for_quantize/ cp 1_model_caffe/v3.prototxt 2_model_for_quantize/v3.prototxt python 1.5_proto_patch.py 2_model_for_quantize/v3.prototxt 416 416 5_file_for_test/calib.txt 5_file_for_test/calib/ bash -v 2_quantize.sh # step 3: compile ELF file # cp 3_model_after_quantize/ref_deploy.prototxt 3_model_after_quantize/deploy.prototxt python 2.5_proto_patch.py 3_model_after_quantize/deploy.prototxt bash -v 3_compile.sh # step 4: prepare the package for the ZCU102 board cd .. cp example_yolov3/4_model_elf/dpu_yolo.elf yolov3_deploy/model/ tar -cvf yolov3_deploy.tar ./yolov3_deploy gzip -v yolov3_deploy.tar
実行
ここまで修正すれば、自前のデータを読み込むようになったので、tutorial.shを実行してデプロイ!です。
感覚的には2の量子化は一瞬で、3のコンパイルが結構時間かかるっぽいです。
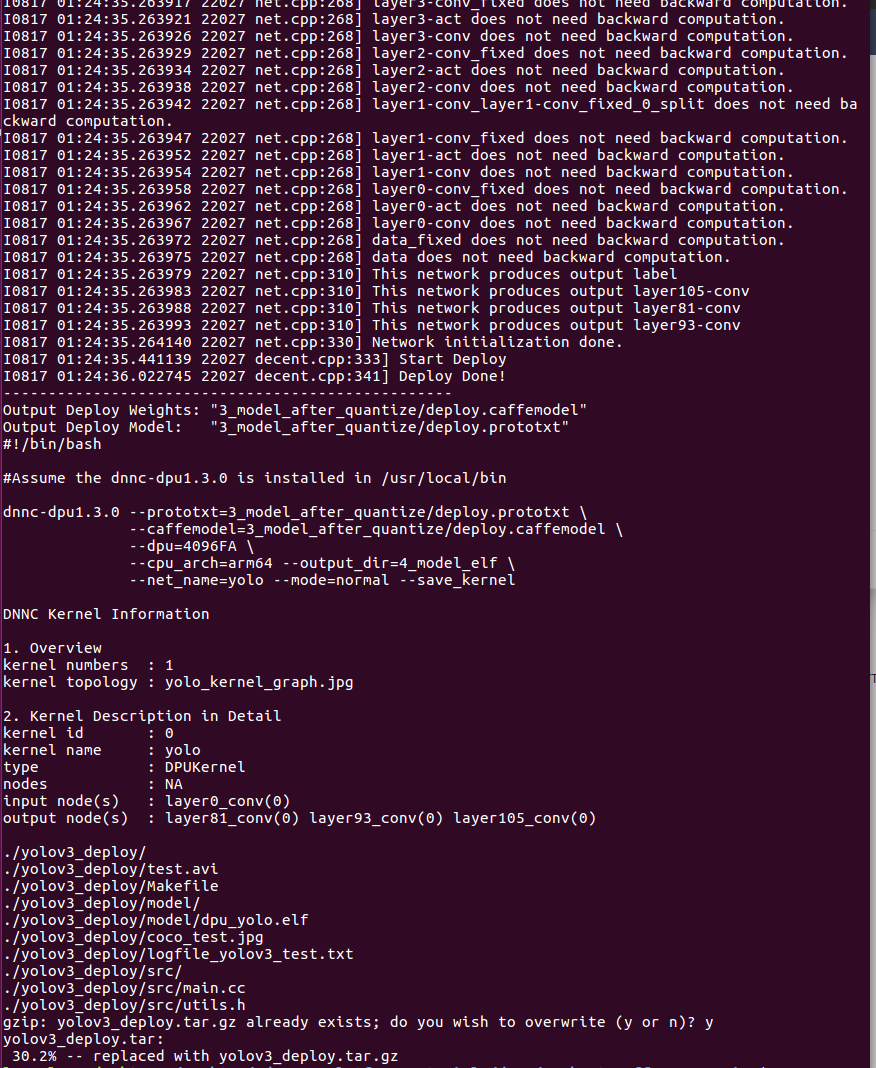
エラーが特にでていなければ終了。最後にデプロイしたデータをtar.gzに圧縮されるか聞かれます。
生成されたyolov3_deploy/model/dpu_yolo.elfが生成されたネットワークのようです。
yolov3_deploy内のテストデータ(coco_test.jpg, test.avi)は元々のデータなので手作業で差し替えました。
わりと1日ですんなりできてしまった。次回は実機で動作確認しようと思います。
ZC102じゃなくてUltra96だけどうまくいくかな?